본 문서는 최근 줌닷컴(zum.com)에 런칭된 신규 서비스 '셀럽NOW' 에 대한 내용을 다루기 위해 작성된 글입니다.
셀럽NOW는 유명 연예인들의 뉴스와 사진을 고품질 이미지 순(그리드) 또는 최신 이벤트 순(타임라인)으로 제공하여 포털 사용자에게 더 높은 수준의 검색 결과를 보여줌으로써 서비스 만족도를 높일 수 있는 시스템입니다.
시스템 개발에는 최신 딥러닝 기술(Face Detection, Semantic Segmentation, Image Classification, Image Quality Assessment) 뿐만 아니라 자연어 처리(NLTK, 문장분리, 구문분석, 인명사전, 대표인명 추출) 및 영상 처리(Color Science, Image Classification, Image Analysis) 기술이 접목되었습니다. 각 기술들의 수학적 내용은 복잡하고 어렵지만, 그런 복잡하고 어려운 이야기보다 각 기술들을 포털 서비스에 어떻게 적용하였는지 기술 응용 측면에서 최대한 쉽게 서술하고자 했습니다.
서비스 기획의도
포털에서 이슈 검색어를 살펴보면 그림 1과 같이 연예인의 이름이 꾸준히 상위에 노출되는 것을 볼 수 있습니다. 이처럼 인터넷 이용자들은 연예인에 대한 관심이 아주 높고, 각자 선호하는 연예인의 최근 소식 및 사진을 지속적으로 검색하며 꾸준히 접하고 있습니다. 이러한 사용자들의 검색 니즈에 대응하기 위해서는 연예인의 최근소식 및 사진을 효과적으로 제공할 수 있는 시스템의 개발이 필요했습니다.

서비스 제공방식
이용자가 원하는 연예인 사진을 적절하게 제공하기 위해, 아래와 같은 두가지 방식을 활용했습니다.
첫번째, 그리드 방식입니다. 뉴스 이미지를 그림 2와 같이 격자 형태로 나열하되, 고품질의 이미지를 상위에 노출 시키는 방식입니다. 사용자가 보고자하는 연예인 이미지 중 고품질 이미지를 우선적으로 제공함과 동시에 그림 3과 같이 연관 이미지를 묶어서 보여줌으로써 사용자 만족도를 높일 수 있는 UI 입니다.


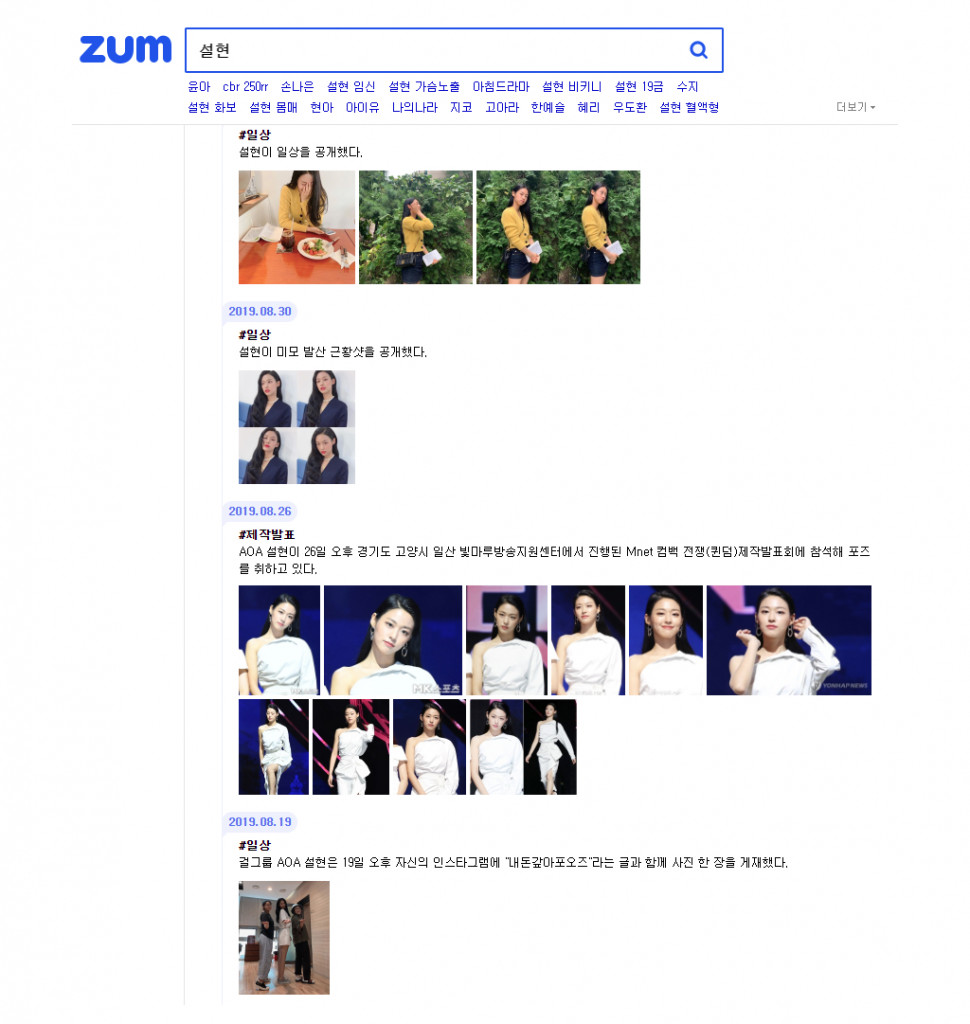
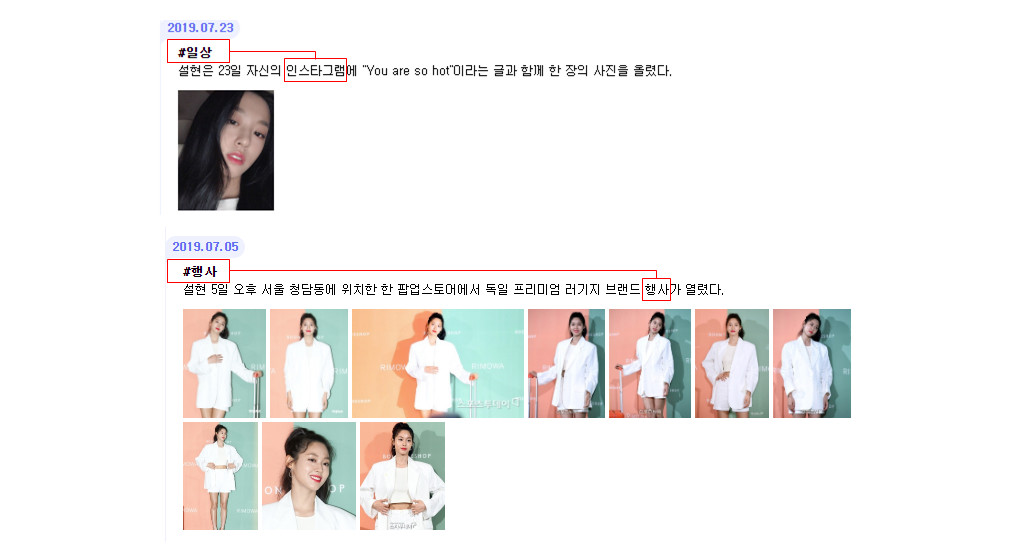
두 번째는 타임라인 방식입니다. 뉴스 이미지를 그림 4와 같이 수직방향으로 나열하되, 최신 이벤트 순으로 노출하는 방식입니다. 연예인의 최신 근황을 제공해 줄 뿐만 아니라 날짜/이벤트에 따라 구분지어 제공함으로써 사용자의 만족도를 높일 수 있는 UI입니다.
시스템의 구성
셀럽 NOW는 연예인 이름이 쿼리로 입력되었을 때 위에서 언급한 타임라인 및 그리드 UI 를 제공해주는 서비스입니다. 즉, Input 은 연예인 명이며 Output은 뉴스 이미지 집합인 것입니다.
Input 쿼리가 입력되었을 때 문서가 노출되는 알고리즘은 아래와 같이 크게 3단계로 구분됩니다.
- Query에 해당하는 문서를 탐색하는 단계
- 중복 이미지를 제거하고, 연관 이미지끼리 클러스터링 하는 단계
- 뉴스 문서를 정렬하여 노출 순서를 결정하는 단계
Query 문서 탐색
Query에 해당하는 뉴스 문서 탐색은 뉴스 문서에 나오는 연예인 명의 역색인으로 해결할 수 있습니다. 따라서 뉴스 문서가 어떤 연예인에 대한 문서인지, 특히 주체가 누구인지 파악하는게 중요합니다.
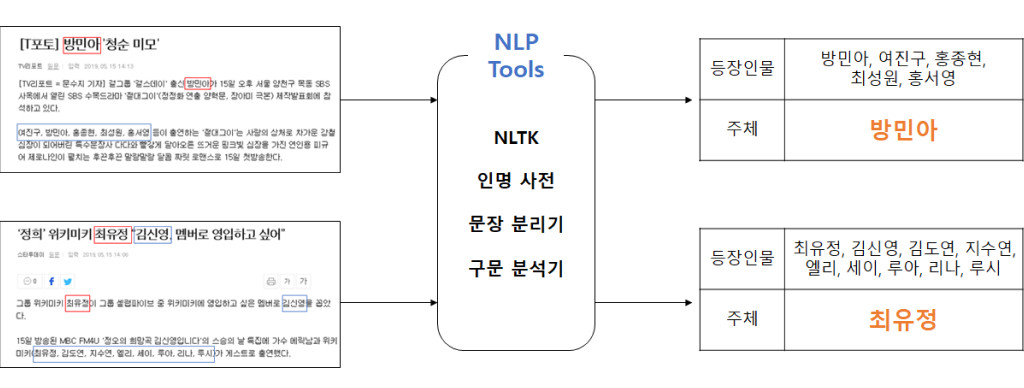
여기서 주체란 문서의 주인공을 뜻합니다. 문서 내에 주체가 언급되는 것은 자명하지만, 언급되는 인물 모두가 주체가 되는 것은 아닙니다. 아래 그림 5의 예시에서 등장인물은 [방민아, 여진구, 홍종현, 최성원, 홍서영] 이지만 뉴스에서 이야기하고자 하는 인물은 “방민아” 입니다. 즉, 주체는 “방민아” 이며, 나머지는 단순 등장인물인 것입니다. 즉, 뉴스의 등장 인물 중 누가 주체인지를 판단할 수 있어야 합니다.

주체 검출 방법은 그림 6과 같습니다. NLTK, 인명사전, 문장분리, 구문분석 등 다양한 자연어처리 기술을 적용하여 문서 내 등장 인물을 찾고 그 중에 누가 주체인지를 판단하게 됩니다.
중복 이미지 제거 및 연관 이미지 클러스터링
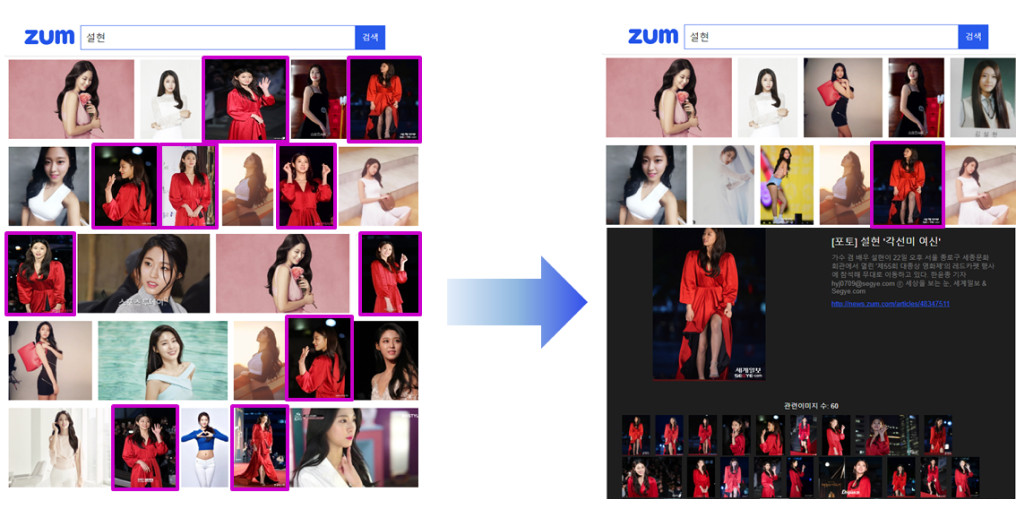
뉴스 문서들을 보다 보면 서로 다른 문서임에도 불구하고 문서 안에 포함된 이미지가 비슷한 경우가 굉장히 많습니다. 사용자에게 비슷한 이미지를 모두 보여주면 시스템의 품질도 굉장히 낮아보일 뿐더러, 필요없는 데이터 양의 증가로 인하여 처리 속도도 느려지게 됩니다.
따라서 그림 7과 같이 비슷한 이미지를 하나로 묶어서 보여주고, 동일한 이미지의 경우 하나만 노출시켜 시스템의 품질을 높일 필요가 있었습니다. 이를 위해 이미지 유사도를 나타낼 수 있는 특성을 임베딩하고, 임베딩된 벡터를 클러스터링했습니다.
Feature Vector Extraction
이미지 특성을 임베딩하기 위해 유사한 이미지가 나오는 경우를 분석하여 다음과 같이 세 가지 케이스로 분류하였습니다.
첫 번째, 같은 장소에서 같은 배경을 각도만 달리하여 사진을 찍거나, 시간차를 두고 사진을 찍은 경우입니다.그림 8과 같이 기본적으로 인물과 장소가 동일하기 때문에 영상 전반에 걸친 컬러가 비슷할 수 밖에 없습니다. 따라서 영상의 컬러 특성을 분석하여 임베딩 벡터를 제작하였습니다.

두 번째, 사진 촬영 장소 또는 각도가 다르지만 인물의 포즈는 비슷한 경우입니다. 그림 9와 같이 주요 객체 외 배경의 컬러는 다르지만 객체의 형태 또는 구도가 매우 비슷합니다. 따라서, 영상 내 객체의 Shape 특성 등을 분석하여 임베딩 벡터를 제작했습니다.

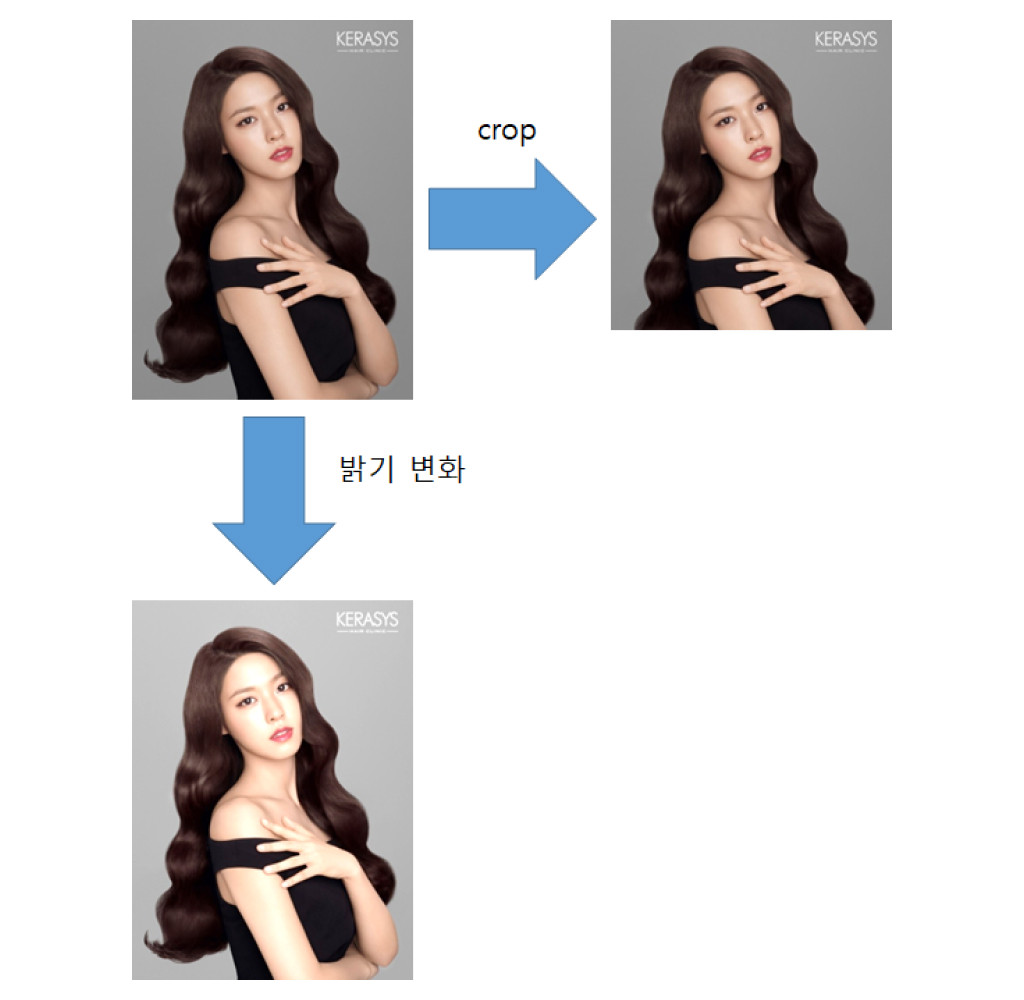
마지막으로 영상의 원본은 동일하지만 Crop, Resizing, Enhancement, Shifting, Compression 등의 왜곡이 발생한 경우입니다. 그림 10과 같이 영상을 Cropping 했거나, 밝기 또는 색을 변화시켜 왜곡이 발생하였지만 영상의 전체적인 구도 또는 객체 배열 형태가 비슷합니다. 따라서, 영상의 Spatial 특성이 아닌 주파수 특성을 분석하여 임베딩 벡터를 제작하였습니다.
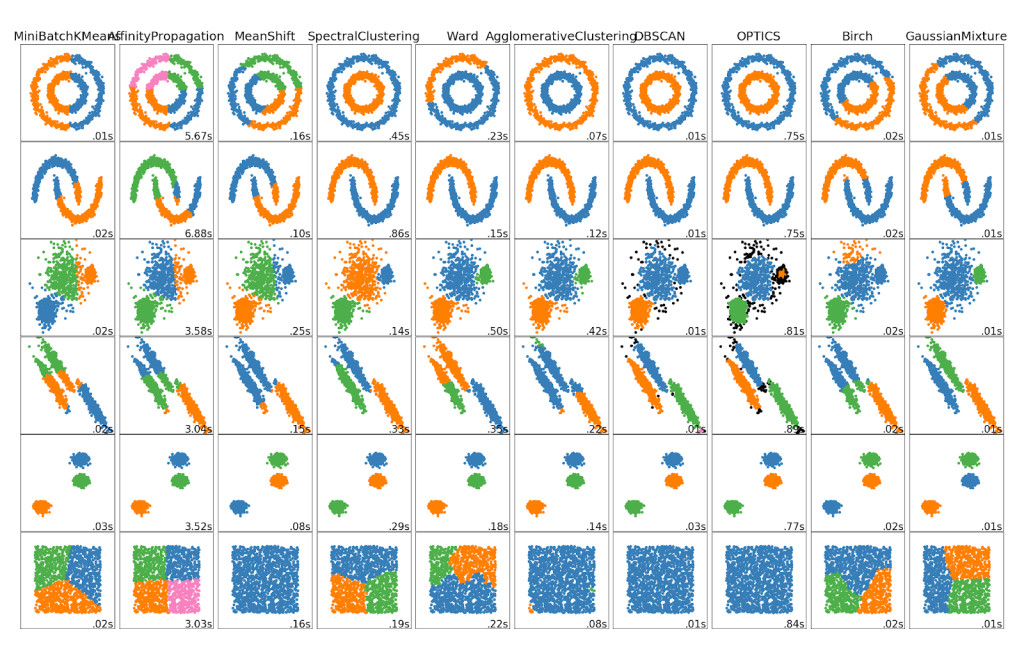
이미지 클러스터링
위에서 정의된 세 가지 임베딩 벡터를 활용하여 이미지 클러스터링을 수행했습니다. 이미지 클러스터링에는 그림 11과 같이 매우 다양한 알고리즘이 존재합니다. 본 시스템에서는 각 임베딩 벡터 간 특성을 고려하여 두 가지 이상의 클러스터링 알고리즘을 적용한 뒤 각각의 결과를 앙상블하였습니다.
뉴스 문서 정렬
쿼리에 해당하는 문서 탐색, 중복 이미지 제거, 유사 이미지 클러스터링 과정을 거쳐서 하나의 주체에 대하여 여러 개의 클러스터가 만들어졌습니다. 이제 각 클러스터를 사용자에게 제공할 때 어떤 순서로 어떻게 제공하는지 결정하는 과정이 필요합니다.
문서 제공 방법에는 두 가지 방법이 있습니다. 첫번째는 이미지 기반 정렬 방식을 적용하여 고품질의 이미지를 상위에 보여주는 그리드 UI, 두번째는 이벤트 기반 정렬 방식을 적용하여 이벤트 발생 시간 순서대로 보여주는 타임라인 UI입니다.
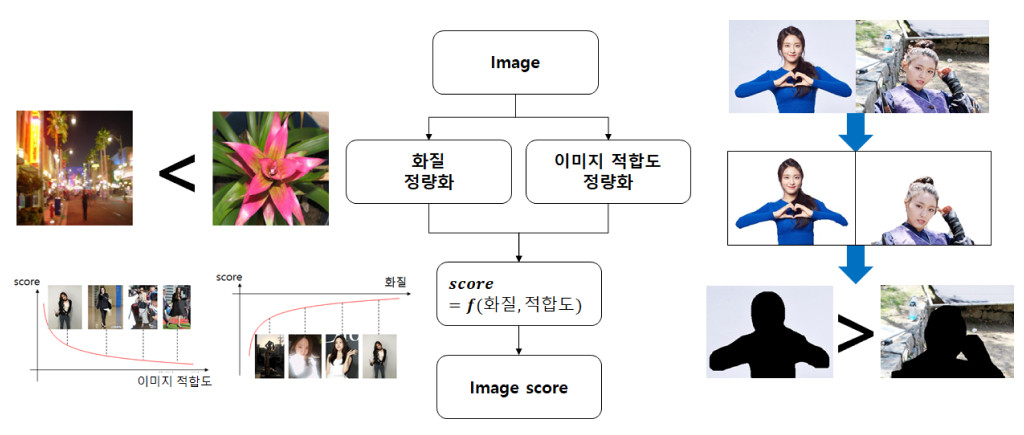
이미지 기반 정렬
그림 12와 같이 이미지를 품질 순서대로 정렬하여 사용자에게 보여주는 방법입니다. 사용자에게 고품질의 연예인 이미지를 보여줌으로써 검색 결과의 만족도를 높일 수 있습니다.

이미지 기반 정렬을 하기 위해 이미지 품질에 대한 딥러닝 모델을 적용하였습니다. 하지만 셀럽NOW는 인물 이미지에 특화된 시스템이기 때문에 일반적인 이미지가 아닌 인물 이미지에 대한 품질 정의가 필요합니다. 사진관에서 증명사진을 찍거나, 연예인의 화보를 보면 배경이 아주 깔끔하고 깨끗한 것을 볼 수 있습니다. 배경이 깔끔해야 인물이 부각되고 인물 자체에 시선이 집중되어 인물 이미지의 품질이 높아지는 것입니다. 즉, 배경의 특징에 따라 인물 이미지의 품질이 달라지게 됩니다. 따라서 배경의 특징을 모델링하여 이미지의 품질을 정량화함으로써 셀럽 NOW에 특화된 모델을 제작하였습니다.
이벤트 기반 정렬
그림 14와 같이 이미지를 이벤트 발생 시간 순서대로 정렬하여 사용자에게 보여주는 방법입니다. 사용자에게 연예인의 최신 근황을 제공할 뿐만 아니라 이벤트의 카테고리 종류까지도 분류하여 제공함으로써 사용자의 만족도를 높일 수 있습니다.

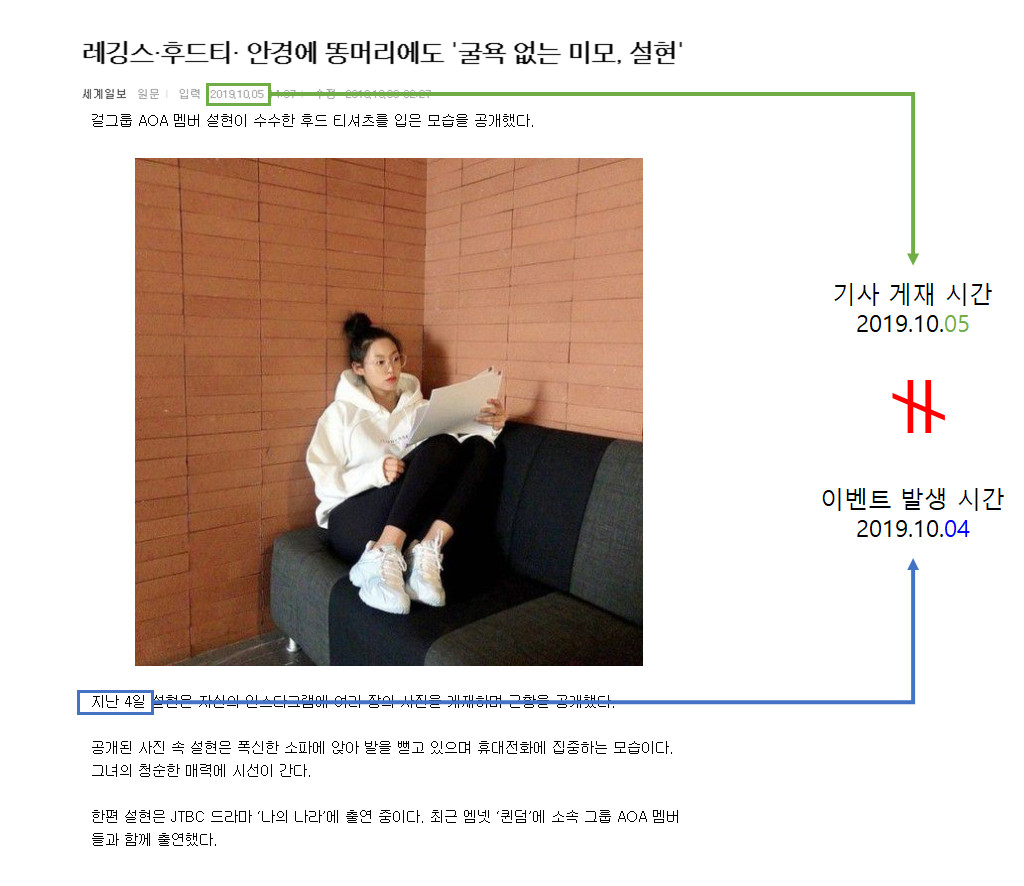
이벤트 시간 정렬을 하기 위해서는 뉴스 이벤트가 발생한 시간을 구해야 합니다. 뉴스 문서에는 문서가 게재된 시간이 명시되어 있지만 그림 15처럼 실제 이벤트 발생 시간과 기사 게재 시간이 다른 경우가 많습니다. 정확한 이벤트 발생 시간을 추출하기 위해서 본문 내 시간 정보와 기사 게재 시간 정보를 활용하였습니다.
하지만, 이벤트 시간이 동일하다고 해서 동일한 이벤트 아닙니다. 활동이 왕성한 스타의 경우 하루에 여러 개의 이벤트 활동을 하는 경우가 흔합니다. 여러 이벤트들을 혼합해서 제공하면 시스템의 품질이 떨어지게 됩니다. 따라서, 이벤트 시간 뿐만 아니라 그림 16과 같이 이벤트 카테고리도 같이 분류할 필요가 있습니다.
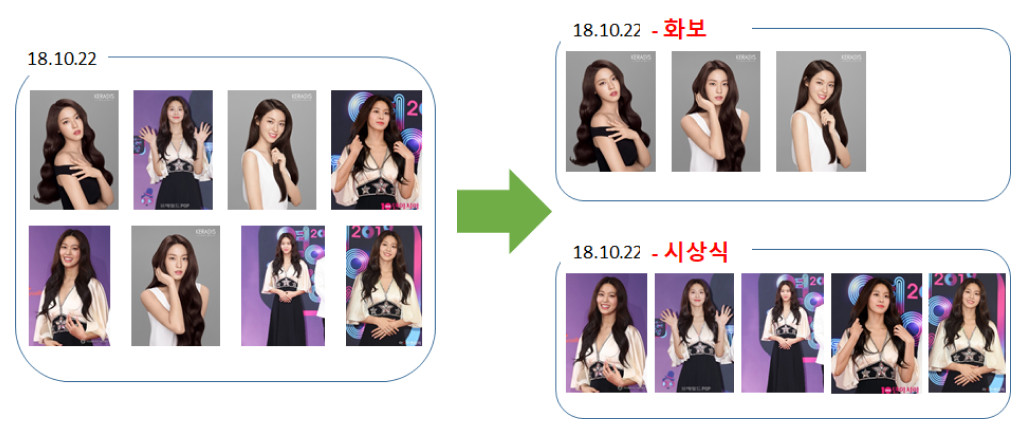
연예 뉴스 이벤트는 화보, 시상식, 입출국, 일상, 행사, 공연 등 굉장히 많은 카테고리로 분류할 수 있습니다. 표현이 정확하고, 전달하는 바가 명확해야 하는 뉴스 문서의 특성 상 그림 17과 같이 대부분의 뉴스 본문에 카테고리에 대한 힌트가 포함되어 있습니다. 따라서 본문 내 텍스트 분석만으로도 카테고리 분류가 가능합니다. 본 시스템에서는 Decision Tree를 사용하여 이벤트 카테고리를 분류하였습니다.
결론
셀럽 NOW는 스타 연예인의 고품질 이미지와 최근 소식을 찾는 사용자들의 니즈에 대응하기 위하여 연예 뉴스 문서를 분석하고, 사용자에게 보다 나은 검색 결과를 제공하기 위하여 개발된 시스템입니다.
시스템의 개발에는 최신 딥러닝 기술 뿐만 아니라 고전적인 자연어 처리 및 영상 처리 기술이 사용되었습니다. 특히 자연어 처리와 영상 처리 기술을 접목시켜 각 데이터를 다루는 함수의 단점을 보완함으로써 시스템의 전반적인 성능을 향상시킬 수 있었습니다.
주요 개발 내용은 다음과 같습니다.
- 뉴스 문서의 주체 추출 기술 개발 및 주체 불일치 문서 제거 기술 개발
- 인물 이미지를 품질 순서대로 보여줄 수 있는 이미지 스코어링 기술 개발
- 중복된 이미지를 제거하여 시스템의 성능을 높일 수 있는 중복 이미지 제거 기술 개발
- 비슷한 이미지를 클러스터링 함으로써 연관 이미지 제공이 가능한 이미지 클러스터링 기술 개발
- 뉴스 문서의 이벤트 발생 시간 추출 기술 개발
- 뉴스 문서의 이벤트 카테고리 분류 기술 개발
현재는 연예 뉴스 대상으로만 하고 있으나, 향후 문화, 스포츠 등으로 적용 범위를 넓혀나갈 계획에 있습니다. 또한 연예인 얼굴 인식 기술, 동명이인 처리 등의 기술을 적용하여 시스템의 성능을 보완해 나갈 예정입니다.
현재 셀럽 NOW는 zum.com 에서 서비스되고 있으니 많은 이용 부탁드립니다. 감사합니다.
참고문헌
[1] Jain, Anil K. (1989). Fundamentals of Digital Image Processing. New Jersey, United States of America: Prentice Hall
[2] Mathematical morphology: from theory to applications, Laurent Najman and Hugues Talbot. ISTE-Wiley. 2010
[3] John Canny, A Computational Approach to Edge Detection, IEEE, 1986
[4] International Color Consortium, Specification ICC.1:2004-10 (Profile version 4.2.0.0) Image technology colour management — Architecture, profile format, and data structure, 2006
[5] Sharma, G. (2004). The CIEDE2000 Color-Difference Formula: Implementation Notes, Supplementary Test Data, and Mathematical Observations
[6] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao, Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks, IEEE signal processing, 2016
[7] Jiankang Deng, Jia Guo, Xue Niannan, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. CVPR, 2019
[8] Hossein Talebi, Neural Image Assessment, IEEE, 2018
[9] Sebastian Bosse, Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment, IEEE, 2016
[10] C Szegedy, Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 2016
[11] Satendra Pal Singh, Gaurav Bhatnagar, A robust image hashing based on discrete wavelet transform, IEEE, 2017
[12] M. de Berg, A. Gunawan, and M. Roeloffzen, Faster dbscan and hdbscan in low-dimensional euclidean spaces, in International Symposium on Algorithms and Computation, 2017
[13] D. Comaniciu and P. Meer, Mean shift: A robust approach toward feature space analysis, IEEE Trans, Pattern Anal, Machine Intell., 24:603–619, 2002
[14] Ester, Martin; Kriegel, Hans-Peter; Sander, Jörg; Xu, Xiaowei. Simoudis, Evangelos; Han, Jiawei; Fayyad, Usama M. (eds.). A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). AAAI Press. 1996
[15] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI, 2017