본 글은 AI 가상피팅 기반 안경쇼핑앱 '라운즈'에 최근 추가된 안경 검색 서비스 'Glass Finder'의 개발기를 공유하고자 작성된 글입니다.
지난 1부에서는 메트릭 러닝 기반 안경 검색 프로젝트(서비스명: Glass Finder)의 전반적인 개발 과정에 대해 다루었습니다. 이번 2부에서는 먼저 메트릭 러닝 기술의 발전 동향을 알아보고, 어떤 기술이 이번 프로젝트에 적용되었는지 모델 구조를 살펴보고자 합니다. 또한, 모델 학습 과정에서 겪은 어려운 점들과 기술 이슈들을 함께 소개하겠습니다.
1. 메트릭 러닝(Metric Learning)의 발전 동향
먼저 메트릭 러닝(문제 정의 부분은 1부 내용 참조)의 최근 발전 동향에 대해 살펴 보도록 하겠습니다. 이 분야는 네트워크의 구조보다는 손실함수(Loss Function)를 변경하는 방식으로 발전하였습니다. 손실함수의 발전 과정은 <그림1> 을 보면 알 수 있습니다.
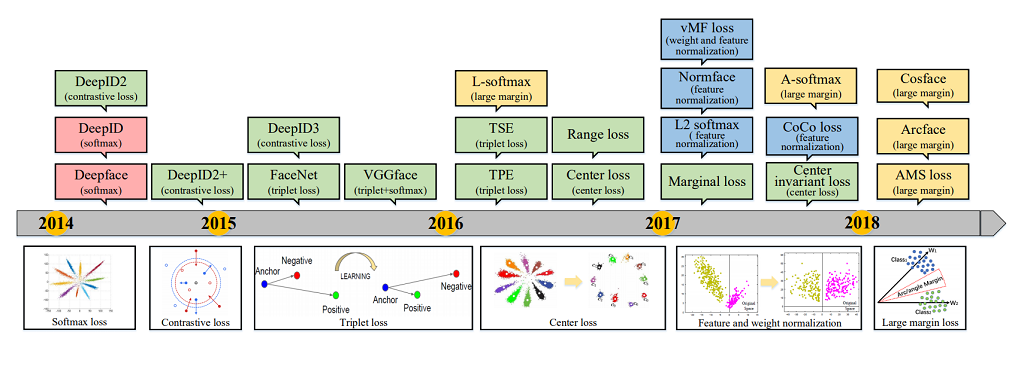
각 단계를 세부적으로 살펴보면 아래와 같습니다.
- Softmax loss : 딥러닝이 컴퓨터 비전의 많은 문제를 해결하기 이전에는 주로 SVM(Support Vector Machine) 알고리즘이 많이 사용되었습니다. 딥러닝 초창기에도 SVM의 Hinge 손실함수가 꽤 여러 곳에 사용되었지만, 요즘은 특별한 이유가 아니면 softmax 손실함수가 주로 활용되고 있습니다. 메트릭 러닝에서도 2014년도 DeepFace, DeepID 계열에서 softmax 손실함수가 다수 활용된 것을 볼 수 있습니다. softmax 함수는 출력값이 확률 분포의 모양을 갖도록 모두 양수로 만들고 그 값의 합이 1이 되도록 하는데요. softmax 함수의 결과값 분포와 정답 라벨 분포와의 유사도를 cross entropy로 측정함으로써 손실함수를 계산할 수 있습니다.
- Contrastive loss : softmax 손실함수를 사용하는 경우, 클래스들이 적당한 선(정확히는 평면)으로 구분되기만 하면 학습이 더 이상 의미있게 진행되지 못하는 단점이 있었습니다. 이런 단점을 개선하기 위해 DeepID2, DeepID3 에서는 동일 클래스에 속한 이미지들의 feature embedding 값들끼리 좀 더 모이도록 하기 위한 contrastive loss가 사용되었습니다. 두 데이터를 쌍으로 입력하고, 두 데이터의 feature 임베딩 값 간의 거리를 계산하는 방식인데요. 두 데이터가 동일한 클래스에 속하는지 여부에 따라 거리값에 대한 손실값 할당을 다르게 하여 임베딩 공간에서의 거리를 조정합니다.
- Triplet loss : FaceNet 에서는 contrastive loss 의 학습 효율을 증가시키기 위한 방법이 제안되었습니다. 학습 데이터 쌍을 2개를 이용하는 것이 아닌, 3개를 이용하는 방법(Triplet loss)입니다. 이 때, 2개는 동일 클래스에 속하도록 합니다. 3개의 데이터를 선택하는 부분이 복잡하긴 하지만, 성능이 좋았기 때문에 많은 메트릭 러닝에서 사용되었습니다.
- Center loss : Triplet loss 는 성능은 좋았으나, 거리 비교를 위해 매번 입력되는 데이터 쌍을 적절히 선택해 주어야 했기 때문에 학습 데이터 구성이 까다로웠습니다. center loss 에서는 각 클래스들의 중심과의 거리를 비교하는 방식을 도입하여 데이터 쌍 선택 과정의 불편함을 개선하였습니다. center loss 도입으로 학습 데이터 구성의 편의성 뿐만 아니라 성능도 개선되었습니다.
- Feature and weight normalization : 일반적으로 거리 계산 시 feature 벡터의 유클리디안 거리를 사용했지만, Feature and weight normalization 의 도입으로 feature 벡터의 길이를 일정하게 유지하여 정규화 적용을 통해 성능 향상을 이뤄 내었습니다.
- Large margin loss : 임베딩 벡터와 클래스 중심 간의 거리에 따른 손실값 계산 시 공평하게 거리를 계산하는 것이 아니라, 정답 클래스 중심까지의 거리를 계산할 때 margin값을 더해주어 더 혹독하게 모델을 훈련시키는 방법(Large margin loss)이 개발되었습니다. 이를 통해 feature vector 가 메트릭 러닝이 필요로 하는 "동일 클래스 내에서는 더 잘 모여있고, 다른 클래스와는 더 멀리 떨어지는 곳으로" 임베딩되게 되었습니다.
[참고] 활용 가능한 공개 구현 코드
앞서 살펴본 '메트릭 러닝의 손실함수 적용'을 PyTorch 프레임워크를 이용하여 구현한 코드도 GitHub에 공개되어 있습니다. API 문서화도 잘 되어 있고 각 구현에 대한 논문 링크도 충실히 달려 있기 때문에 메트릭 러닝 구현을 본격적으로 공부해보고 싶은 분들에게 유용하다고 생각하여 소개합니다.
2. Glass Finder 모델 구조 설명
이번 안경 검색 프로젝트에서는 최신 메트릭 러닝 동향인 Large margin loss 개념을 구현한 ArcFace 기법을 사용했습니다. ArcFace 의 네트워크 구조 자체는 매우 간단합니다. 일반적인 CNN 백본 네트워크에 메트릭 러닝 레이어를 연결시킵니다. 이 때 CNN 백본의 임베딩 벡터는 512차원을 사용했습니다. 임베딩 메트릭 러닝 기법 적용 외에도, 여러 task를 한 번에 훈련시키는 멀티 테스킹 기법을 <그림3>과 같이 구현했습니다.
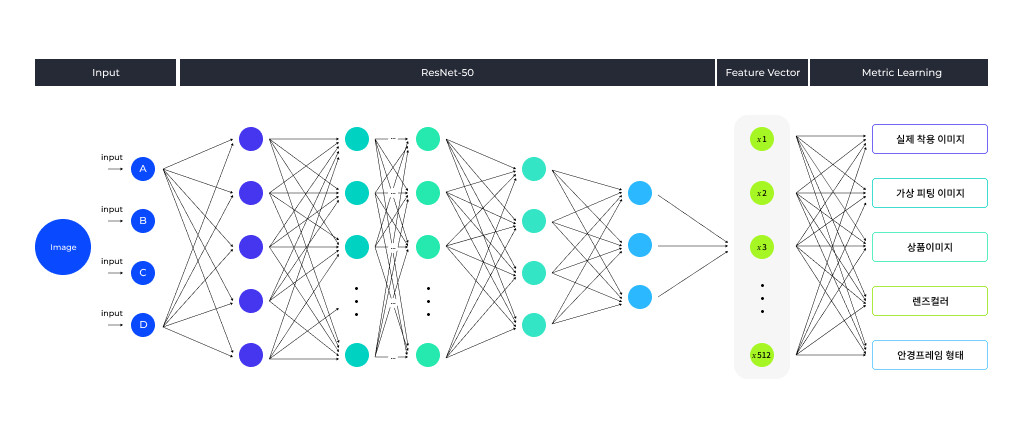
총 5개의 task를 동시에 훈련시켰고, 각각의 task는 아래와 같습니다.
- 실착용 이미지 : 실제 사람이 안경/선글라스를 착용한 이미지에 대해 해당 상품 번호를 맞추게 하는 task입니다. 실착용 이미지 확보가 어려웠기 때문에 이 task를 위한 입력 데이터 개수는 수천개 수준으로 매우 적은 편이었습니다. 또한, 실제 착용 이미지가 없는 제품들도 상당히 많아 학습에 어려움을 겪었습니다.
- 가상피팅 이미지 : 실착용 이미지 수집에 한계를 느껴 데이터 확보를 위해 라운즈 서비스에 적용된 가상피팅 모듈을 활용했습니다. 이를 통해 수십만장 이상의 안경 착용 데이터를 자체적으로 생성하여 훈련 데이터로 사용한 task입니다.
- 상품 이미지 : 온라인 쇼핑몰에서 상품 소개를 위해 사용하는 제품 사진을 훈련 데이터로 사용한 task입니다.
- 렌즈 컬러 그룹핑 : 안경의 렌즈 컬러만을 집중적으로 학습시키기 위해 라벨 정보를 컬러 기반으로 수정하여 학습시키는 task입니다. 렌즈 색상이 같으면 같은 클래스로 학습시키되, 그룹핑 클래스를 임벡딩 벡터의 512차원 전체가 아닌 128차원만을 사용했습니다.
- 안경 프레임 형태 그룹핑 : 안경 프레임의 형태만을 집중적으로 학습시키기 위해 라벨 정보를 형태 기반으로 수정하여 학습시키는 task입니다. 안경의 형태가 같으면 같은 클래스로 학습 시키되, 렌즈 컬러 task와 동일하게 128차원만을 사용했습니다.
3. 메트릭 러닝 학습의 기술적 특징
구면 임베딩
위 설명한 구조 상에서 임베딩 벡터는 normalize를 통해 모두 구면 공간에 분포하게 됩니다. 처음 랜덤한 값으로 초기화 하는 경우, <그림4> 에서 보듯이 약 90도 근처에 분포하게 됩니다. 우리가 흔히 접하는 2차원, 3차원 공간에서는 여러 벡터들의 사잇각이 90도 근처를 유지하도록 배치하는 것이 불가능하죠. 반면 512 차원에서는 수십만개의 백터를 무작위로 분포시켜도 대부분의 벡터들이 서로 약 90도의 사잇각을 유지하고 분포하게 됩니다. 이처럼 고차원 공간에 분포한 벡터들은 우리의 직관과 대비되는 성질들이 꽤 많이 있습니다. 딥러닝 분야에서는 이와 같이 우리의 직관과 대비되지만, 딥러닝 학습과 연관이 있는 고차원 공간의 특징들을 올바르게 파악하는 것이 중요합니다.
평균값과 분산 모두 작아지게 하는 것이 학습 목표이기 때문에, 학습이 진행됨에 따라 중심 벡터와 해당 클래스의 feature 벡터들 간의 사잇각의 분포가 점점 작아지게 됩니다. <그림 4> 와 같이 학습이 완료되는 단계에서는 30도 40도 부근으로 수렴하게 됩니다.
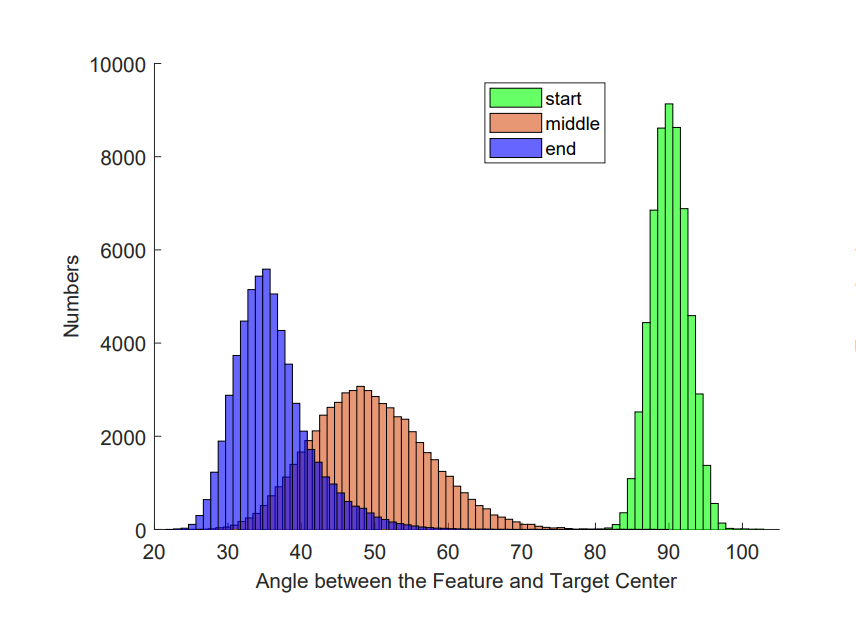
이 외에도 훈련 시 겪게 되는 특이한 부분을 두 가지 소개하겠습니다.
- 삼각함수의 정의역을 벗어난 값에 대한 예외 처리 : 두 벡터가 이루는 사잇각을 알아내기 위해서 먼저 두 벡터의 내적값을 이용해 cos 값을 구합니다. cos의 역함수 acos을 사용해 사잇각을 구합니다. 이와 같이 여러 삼각함수를 사용하게 되는데, 이 때 각 함수 별로 90도, 180도와 같이 정의되지 않은 구간이 존재하게 됩니다. 훈련이 진행되면서 이런 특이값 부근에서 예외가 발생할 수 있기 때문에 예외 처리가 필요합니다. 다만 이때 수학적으로 보다 의미 있는 예외 처리 방식을 고민할 필요는 없습니다. 수백만 번의 입력 데이터 처리 과정에서 어쩌다 한번씩 발생하는 문제이기 때문에 해당 데이터 처리를 건너띄게 하는 손쉬운 방법으로 구현해도 괜찮습니다.
- 손실값 loss 기반 정확도 측정 시 유의할 점 : 각 거리를 이용한 loss 계산시 margin 패널티에 의해서 정답 클래스와의 거리는 더 멀게 측정되게 됩니다. 이 때 측정된 거리를 이용하여 분류 정확도를 측정하게 되는 경우, 학습 초반부에는 랜덤하게 예측한 결과보다 더 낮은 정확도를 나타냅니다. 일반적인 딥러닝 학습 시 코드의 버그 여부 체크 항목 중에는 “학습 초반 정확도가 무작위 예측과 동일한가?” 라는 항목이 있습니다. 일반적으로 학습이 하나도 이루어지지 않은 경우에는 무작위 예측과 동일한 정확도가 나와야 하지만, margin 패널티에 의해서 무작위 예측보다도 더 정확도가 낮게 측정이 되게 됩니다. 이 경우 당황하지 말고 학습을 좀 더 진행시켜 추이를 살펴봐야 합니다.
4. 결론
이상으로 메트릭 러닝 기술 동향부터 모델 구조, 학습과 관련된 기술 이슈까지 살펴 보았습니다.
특정 관점을 가지고 영상의 주제를 분류하는 문제의 경우, 현재 많은 연구가 진행되어 컴퓨터 비전 분야의 가장 기본적인 문제로 볼 수 있습니다. 한 영상에 대해 사람을 찍은 영상인지, 자동차를 찍은 영상인지, 또는 실내에서 찍은 영상인지, 실외에서 찍은 영상인지 등을 쉽게 구분할 수 있죠. 반면, 수많은 과자 영상들에 대해 동일 과자끼리 묶는 문제는 아직까지 높은 수준으로 해결하기는 어렵습니다. 동일 주제에 대해서 좀 더 세부적으로 유사도를 측정하여 클러스터링 하는 문제의 경우, 아직 실서비스에 효과적으로 쓰일 만큼 기술이 성숙되지 못했기 때문입니다.
하지만, 인공지능(AI) 기술이 점점 산업 현장에 많이 쓰이면서 유사도 기반 클러스터링에 대한 수요가 점점 늘어나고 있기 때문에 앞으로 메트릭 러닝 기술 분야의 빠른 발전이 기대됩니다. 이스트소프트 연구소에서도 지속적인 Glass Finder 서비스의 개선과 신규 서비스 개발을 통해 기술 발전에 기여할 것입니다. 많은 관심과 응원 부탁드립니다.
참고문헌
[1] https://arxiv.org/pdf/1804.06655.pdf
[2] https://github.com/KevinMusgrave/pytorch-metric-learning
[3] https://arxiv.org/pdf/1801.07698.pdf
[4] https://arxiv.org/pdf/1811.12649.pdf
[5] http://openaccess.thecvf.com/content_CVPR_2019/papers/Cakir_Deep_Metric_Learning_to_Rank_CVPR_2019_paper.pdf
[6] https://arxiv.org/pdf/1706.07567.pdf
[7] https://www.cs.cornell.edu/jeh/book.pdf