본 글에서는 악성코드 위협 대응 솔루션 'Threat Inside'에 적용된 '행위 기반 악성코드 검색 시스템'의 개발 후기를 다루고자 합니다.
지난 2018년, 점점 고도화되고 지능적으로 진화하는 변종 악성코드에 잘 대처하기 위해 딥러닝 기술을 활용하여 의미적으로 비슷한 악성코드를 검색하는 시스템을 개발하였습니다.
이 시스템은 2018년 10월 정식 출시된 AI 기반 악성코드 위협 대응 솔루션 '쓰렛인사이드(Threat Inside)'의 핵심 기반 기술로 사용되었습니다. Threat Inside는 딥러닝 기술을 활용해 24시간 언제든지 의심되는 파일이나 정보를 분석하고 악성여부나 그 종류를 자동으로 판별하여 유형별 대응 가이드를 제공하는 위협 인텔리전스(CTI) 서비스입니다. 여기서 이 시스템은 신/변종 악성코드를 식별하고 분류하는 '딥코어(Deep Core)' 엔진에 적용되었습니다.
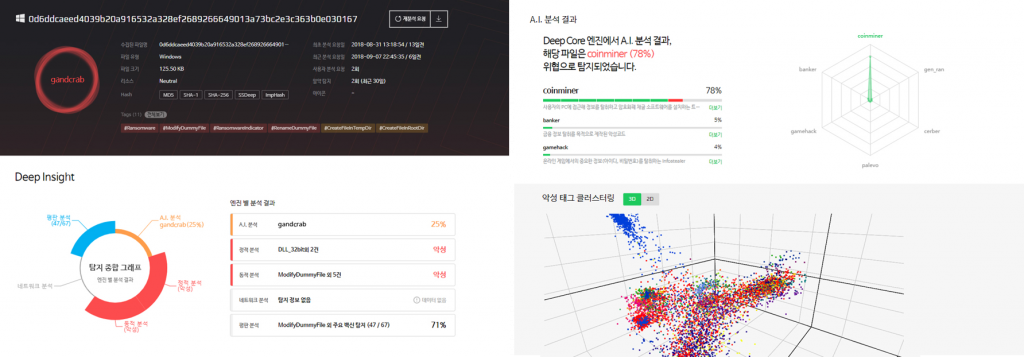
이번 포스팅에서는 이 악성코드 검색 시스템과 관련된 세가지 이야기를 해보려고 합니다.
- 악성코드 검색 시스템의 필요성과 개발동기
- 악성코드 검색 시스템이 의미를 이해(semantics-aware)해야 하는 이유
- 이 시스템을 만들기 위해 시도한 방법과 그 구조
1. 악성코드 검색 시스템의 필요성과 개발동기
지금 이 순간에도 공격자들이 만들어내는 여러 악성코드 생성 도구들로 인해, 수백만개 이상의 변종 악성코드가 매일 새롭게 생성되고 있습니다. 특히 기존에 악성코드 탐지/분류를 위해 주요 사용하던 특징들(code fragments, hashes, file properties, LSH 등)은 완전히 동일한 파일이나 아주 작은 변화에 대해서만 감지할 수 있기 때문에 최근에는 이런 탐지방법을 회피한 고도화된 방식을 거쳐 다양한 신/변종 악성코드가 나타나고 있습니다. 이렇게 기하급수적으로 증가하고 있는 악성코드는 이제 보안 전문가들이 일일히 대응하기 어려운 상태가 되었습니다.
날마다 진화하는 사이버 위협에 맞서 최적의 대응을 하고, 이를 통해 보안 담당자의 업무 피로도를 줄이기 위해서는 무엇보다 위협을 정확히 탐지하고 분석하는 서비스가 필요하다고 생각했습니다. 저희는 파편적으로 존재하는 기존 특징 추출 기법들에 딥러닝 기술을 접목시켜 현재 문제를 해결할 수 있는 응용 시스템을 만들고자 했습니다.
2. 악성코드 검색 시스템이 의미를 이해(semantics-aware)해야 하는 이유
Semantics-aware란 악성코드간의 의미 관계를 feature space에 나타내는 것을 의미합니다. 가장 대표적인 예로 Word2Vec을 들 수 있는데 이는 [그림2]와 같이 단어간의 문맥적 관계를 유지한 채로 단어를 feature space에 표현하는 모델입니다. 이와 같이 우리가 제안한 모델 또한 악성코드간의 행위가 유사하면 가깝게, 다르면 멀도록 feature space에 나타낼 수 있습니다.

악성코드를 탐지하거나 분류를 할 때, semantics-aware가 중요한 이유는 악성코드 도메인의 특징 때문입니다. 예를 들어 ①정상 그림판 실행 파일과 ②Trojan에 감염된 그림판 실행 파일, 마찬가지로 ③Trojan에 감염된 메모장 실행 파일이 있다고 가정했을 때, 정상 그림판과 감염된 그림판의 파일 크기, 아이콘, 헤더 등 대부분 정보가 비슷하더라도 이를 다르다고 구분할 수 있어야 합니다. 또한, 같은 악성코드에 감염된 그림판과 메모장은 비슷한 악성코드라고 판단할 수 있어야 할 것입니다. 이처럼 악성코드 도메인에서는 악성코드의 행위를 기준으로 악성코드 간의 유사도를 나타내야 하기 때문에 '의미를 이해할 수 있는 악성코드 분류/탐지 시스템(Semantics-aware system)'을 갖추는 것이 꼭 필요합니다.
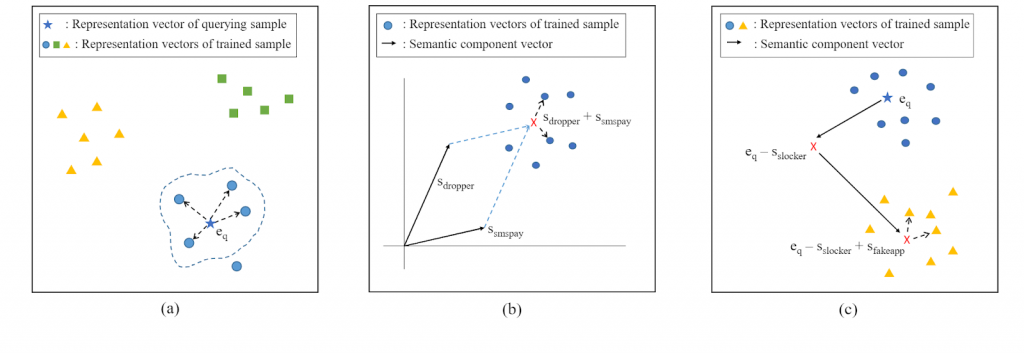
Semantics-aware system에서 가능한 모습은 아래와 같습니다.
- (a)와 같이 샘플을 쿼리로 하여 행위가 비슷한 샘플들을 검색할 수 있습니다.
- (b)와 같이 복수의 행위를 쿼리로 하여 해당 행위들을 갖는 샘플들을 검색할 수 있습니다.
- (c)와 같이 샘플과 행위를 쿼리로 하여, 해당 샘플에 행위를 더하거나 뺀 샘플들을 검색할 수 있습니다.
3. 의미를 이해하는 악성코드 검색 시스템의 개발과정
1) 데이터
먼저, 딥러닝 모델을 학습하는데 가장 중요한 것은 퀄리티있는 데이터의 확보입니다. 저희는 국내 사용자 수 1위 백신 '알약(ALYac)'을 포함한 다양한 채널을 통해 방대한 악성코드 샘플을 수집할 수 있었고, 이스트시큐리티 내 보안 전문가들의 도움을 받아 악성코드의 행위 정보를 분석하여 학습에 사용했습니다.
2) 메트릭 러닝 (Metric Learning)
다음으로, 의미를 이해하는 악성코드 검색 시스템을 만들기 위해서는 우리가 정의한 거리함수를 학습해야 합니다. 거리 함수를 학습한다는 의미는 feature space 상에서 어떤 샘플들은 거리가 멀고, 또 어떤 샘플들은 가까운 지를 가르친다는 것입니다.
메트릭 러닝을 통해, 의미적으로 유사한 샘플들의 거리를 작게, 의미적으로 다른 샘플들의 거리를 멀게 만들도록 학습 시킵니다.
- 구조적 유사도 : 정적 분석 특징 기반(멀웨어 샘플의 크기, 사용된 라이브러리들, 권한들, 엔트로피, 콜그래프 등)
- 의미적 유사도 : 동적 분석 특징 기반(행위, 로그, 패킷 등)
이 과정에서 정적, 동적 특징에 대한 의미적 거리함수를 데이터로부터 학습시키기 위해 딥러닝을 사용합니다. 적절하게 설계된 딥러닝 모델은 학습 데이터로부터 여러 층의 비선형 변환을 통해 우리가 원하는 복잡한 함수를 모사 할 수 있습니다. 우리의 모델의 경우 이를 학습하기 위한 목적함수로 Multi-label Center Loss [2]를 사용했는데 자세한 식은 아래와 같습니다.
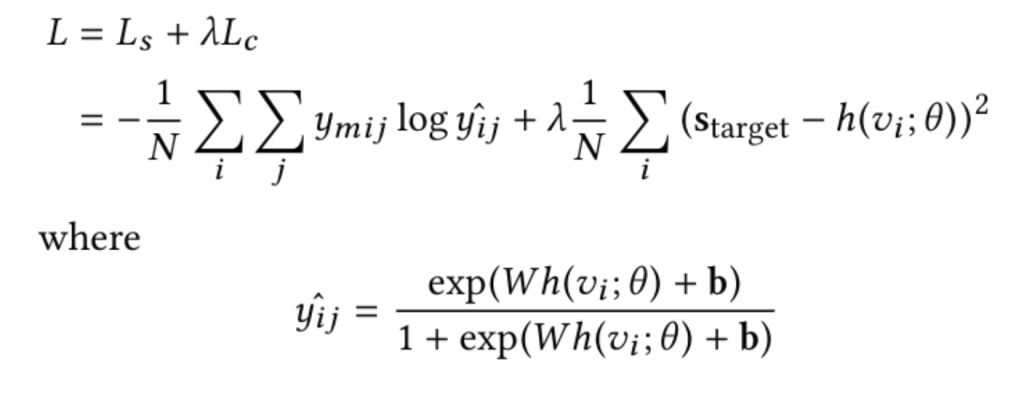
위의 목적함수를 사용함으로써 얻을 수 있는 효과는 다음과 같습니다.
그림의 (a)와 같이 sigmoid cross entropy loss만 사용하게 된다면 악성코드 샘플간의 거리는 고려되지 않은 채 분류만 가능해지도록 모델이 학습됩니다. 하지만 (b)와 같이 center loss를 추가하게 된다면 feature space에서 같은 클래스의 악성코드 샘플간의 거리는 줄어들고, 서로 다른 악성코드 샘플간의 거리는 멀어지게 됩니다. 또한 (c)에서 볼 수 있듯이 같은 악성코드 군에 속하는 악성코드들이 가깝게 나타나는 것을 볼 수 있습니다. 예를 들어, 같은 랜섬웨어(Ransomware) 행위를 하는 Locky와 Cerber가 가깝게 위치하게 되죠.

3) 구조
위에서 소개한 내용을 바탕으로 다음과 같이 악성코드 검색 시스템을 구성했습니다.
- 특징 추출기(Feature extractor) : 악성코드 샘플로부터 정적 혹은 동적 특징을 추출
- 뉴럴 임베더(Neural embedder) : 위에서 추출한 특징으로부터 의미를 이해하는(semantics-aware) 벡터를 출력하는 딥러닝 모듈
- 분류기(Classifier) : 해당 샘플이 가지고 있을 수 있는 행위들의 확률을 계산하는 딥러닝 모듈
- 랭킹 모듈(Ranking module) : 가까운 샘플들을 찾아주는 검색 기능을 수행


5. 결론
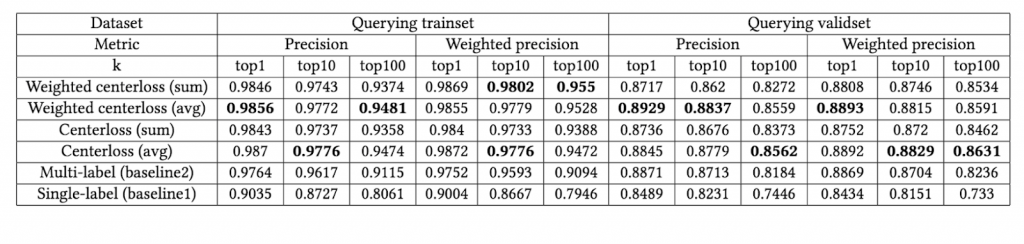
악성코드 검색 시스템을 구성함으로써 [그림3]과 같이 기존 악성코드 분류기로는 할 수 없었던 악성코드의 검색이 가능해졌을 뿐만 아니라, [표1]과 같이 악성코드의 분류 성능도 높아진 것을 확인할 수 있었습니다.
이후 실제 사용자들이 악성코드 데이터를 직접 학습하고 검색해 볼 수 있도록 다음 github 저장소에 소스코드를 배포하였습니다.
마지막으로, 제품의 정식 출시 전인 2018년 8월에는 라스베가스에서 개최된 'Black Hat USA 2018 [3]' 컨퍼런스에서 해당 기술에 대한 발표를 진행할 수 있었는데요. 이 컨퍼런스는 해커 세계에서 가장 유명한 보안 컨퍼런스 중 하나로, 정보보안 전문지를 비롯한 주요 언론의 스포트라이트를 많이 받고 있습니다. 저희는 기술이나 도구를 시연하고 참관객들과 질의응답하는 Arsenal 세션에서 'Deep Information Retrieval for Malware Searching System'이라는 주제로 기술에 대한 발표를 진행했습니다. 이 기회를 통해 많은 보안 전문가들의 피드백을 받을 수 있었고, 다른 세션의 발표를 보며 보안 연구의 트렌드를 파악하고 아이디어를 얻을 수 있는 유익한 시간을 가질 수 있었습니다. 이를 바탕으로 앞으로도 좋은 연구를 통해 보안 기술 발전에 기여하고 이를 공유할 수 있도록 노력하겠습니다.

참고문헌
[1] https://medium.com/analytics-vidhya/implementing-word2vec-in-tensorflow-44f93cf2665f
[2] https://ydwen.github.io/papers/WenECCV16.pdf
[3] https://www.blackhat.com/us-18/