안녕하세요, 이스트소프트 A.I. PLUS Lab입니다. 지난 ICLR 2020에 이어, 이번 ICML 2020에서도 이스트소프트가 논문을 발표하게 되었습니다.
이번 포스팅에서는 ICML 2020에서 발표한 “Being Bayesian about Categorical Probability(범주형 확률에 대한 베이지안 방법론)” 연구에 대해 간단히 소개드리려고 합니다.
연구 목적
본 연구는 기존 딥러닝 모델이 분류 문제 상에서 높은 정확도를 보이지만, 오답에 대해 과한 확신을 가지고 답을 하는 ‘오버 컨피던스(over confidence)’ 현상을 해결하는 것을 목표로 진행되었습니다.
연구 방법
본 연구의 핵심 아이디어는 분류 문제에서 target분포를 생성할 때, 베이지안 관점을 이용하는 것입니다. 베이지안 방법론은 어떤 파라미터를 상수로 보는 대신 확률 변수로 취급하고, 이 파라미터에 대한 사전 확률을 설정한 뒤 데이터를 관측해가며 베이즈룰을 통해 사전 확률을 업데이트하는 방법론을 말합니다.
즉, 본 연구에서 제시하는 belief matching framework는 데이터 라벨을 생성하는 categorical probability를 확률 변수로 취급한 뒤, 학습 라벨 관측에 따른 사후 확률분포를 target 분포로 사용합니다 [그림 1-b]. 구체적으로, conjugate prior와 input-independent prior 를 가정한 뒤, 모든 input에 대해 디리클레 분포(Dirichlet distribution) prior $Dir(\alpha)$를 가정하면 다음과 같은 타겟 분포를 갖게 됩니다. \(Dir (\beta + c^{D}(x)) \propto Cat ({ y_i }) Dir(\beta)\)
이때, 확률 분포의 평균은 위 디리클레 파라미터의 정규화된 값으로 나타나는데, 따라서 기존 softmax cross-entropy에서 사용하는 one-hot encoding [그림 1-a]과 달리 사전 확률 분포에 의해 extreme 한 라벨 분포가 prior $\beta$에 의해 스무딩되는 것을 확인할 수 있습니다. Belief matching framework 에서는 위에 정의된 target 분포와 neural network가 모델링하는 Dirichlet 분포의 KL divergence 를 ELBO(evidence lower bound)를 이용하여 최소화하는 방식으로 neural network를 학습합니다.

연구 결과
위와 같은 연구 방법을 통해 기존 딥러닝 모델이 예측값에 대해 불확실성을 표현할 수 있게 되었고, prior distribution을 통한 정규화 효과를 바탕으로 모델 성능이 향상되는 결과를 얻을 수 있었습니다.
- - 성능 향상 (Supervised learning)
저희가 제안한 belief matching framework를 이미지 분류 벤치마크에 적용했을 때, 표1, 표2와 같이 softmax cross-entropy에 비해 성능이 향상된 것을 확인하였습니다. 이 결과에는 prior를 통한 정규화효과와 디리클레분포를 통해 가능한 모든 target categorical probability가 반영되었습니다. 또한, 이 결과는 weight 파라미터를 확률변수로 취급하는 기존의 베이지안 뉴럴네트워크와 달리 ResNet, ResNext와 같이 큰 모델과 ImageNet과 같은 큰 데이터셋에 scalable함을 보인다는 점에서 의미가 있습니다.
자세한 분석 결과는 논문을 통해 확인하실 수 있습니다.

- - 예측 불확실성 (Uncertainty estimation)
Belief matching framework는 기존 BNN(Bayesian Neural Network)과 달리, categorical probability만 확률변수로 취급하는데요. 과연 이 파라미터만 확률변수로 취급하면서 기존 BNN이 강점을 갖는 uncertainty estimation 능력을 잘 상속하는지를 실험하였습니다.
이때, uncertainty estimation 능력이란 예측과 더불어 해당 예측에 대한 불확실성을 표현하는 능력입니다. 딥러닝 기반의 인공지능 모델은 스스로의 판단을 과신하여 모르거나, 오답도 정답으로 답하는 경향이 있는데요. 이 uncertainty estimation 능력 측정을 통해, 자신이 잘 모르는 샘플에 대해 "잘 모른다"라고 예측값에 대한 불확실성을 표현할 수 있는지 확인해 보았습니다.
먼저, in-distribution sample에 대한 uncertainty estimation 능력을 평가하기 위해 calibration performance를 측정하였습니다. Calibration performance는 네트워크의 예측 카테고리에 대한 확률로 정의되는 confidence 값을 기준으로 예측들을 clustering한 뒤, 각 구간에서의 실제 예측의 정확도와 confidence의 차이로 정의됩니다. 그림 2와 같이 belief matching framework로 네트워크를 학습했을 때, 예측의 confidence가 실제 accuracy와 더 잘 매치가 되는 것과 calibration performance measure인 ECE값이 향상되는 것을 볼 수 있었습니다.
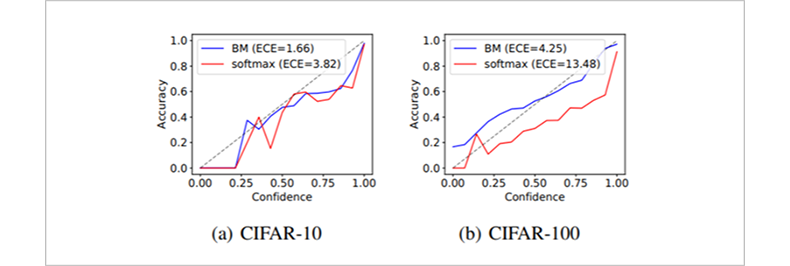
다음으로, out-of-distribution sample에 대한 uncertainty를 측정해 보았습니다. Out-of-distribution sample은 네트워크가 학습한 클래스 중 어떠한 클래스에도 속하지 않기 때문에, uncertainty를 크게 출력하는 것이 이상적입니다. 그림3과 같이 belief matching framework를 사용하여 네트워크를 학습하였을 때, 엔트로피가 최대가 되는 지점의 peak를 만드는 것을 확인할 수 있습니다.

이 결과 외에도 belief matching framework는 transfer learning과 semi-supervised learning에서도 기존 softmax cross-entropy에 비해 향상된 성능을 보이는데, 자세한 내용은 논문을 통해 확인하실 수 있습니다.
마치며
지금까지 ICML 2020에서 발표한 “Being Bayesian about Categorical Probability” 연구에 대해 살펴 보았는데요. 이번 연구는 이미지 분류 뿐만 아니라, 다양한 영역에 활용할 수 있습니다.
이스트소프트에서는 이번 연구 결과를 자회사 엑스포넨셜자산운용에 적용되는 금융 알고리즘에 활용할 예정인데요. 주식 데이터의 경우 다양한 대내외 변수로 인해 미래에 대한 불확실성이 내재되어 있는 만큼, 딥러닝 예측의 불확실성을 고려하여 금융 시장에서의 잘못된 판단으로 인한 손실 가능성을 회피할 계획입니다.
여기까지 읽어주신 많은 분들께 감사 인사드리며, 오늘 소개드린 연구 뿐만 아니라 이스트소프트에서 진행 중인 다양한 연구에 많은 관심과 응원 부탁드립니다.
▶ ICLR 2020 발표 논문 포스팅 보러가기