안녕하세요, AI PLUS 테크블로그입니다. 오늘은 NER의 개념을 살펴보고, 포털에서 이를 어떻게 구현할 수 있을지 알아보려고 합니다.
1. NER 이란?
NER은 Named Entity Recognition의 약자로, ‘개체명 인식’을 의미합니다. 개체명 인식이란 비정형 텍스트의 개체명 언급을 미리 정의된 카테고리(인명, 지명, 시간 등)로 분류하는것을 말하는데요.
오늘은 ‘미쓰에이 수지가 용인 수지에서 단독 공연을 개최하는건 수지에 맞지 않는다고 한다.’라는 예시 문장으로 NER에 대해 자세히 알아보겠습니다. 그림1을 보면 NER 분석을 통해 이 문장 내 ‘수지’와 ‘용인’이라는 단어가 각각 인명, 지명으로 분류된 것을 확인할 수 있는데요.

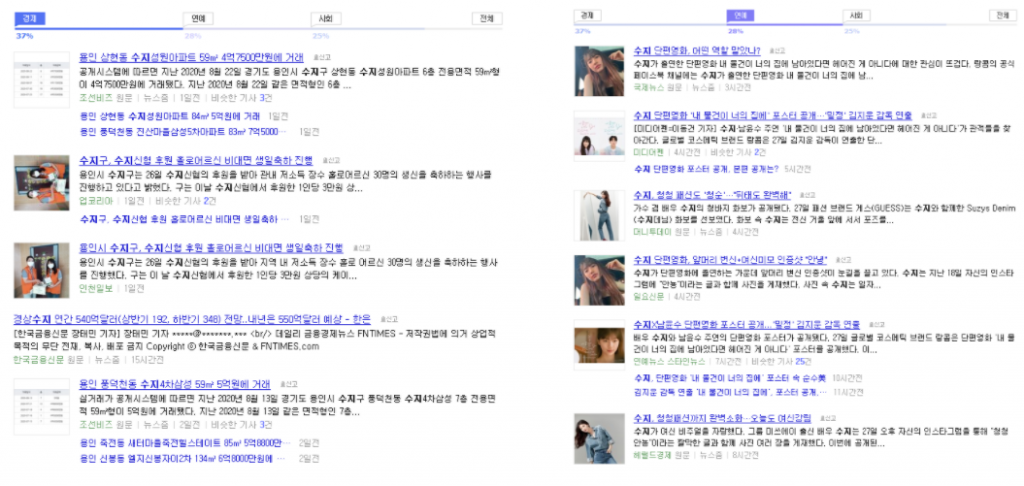
이러한 NER을 어떻게 활용할 수 있을까요? 줌인터넷에서 운영하는 ‘줌닷컴(ZUM.com)’을 예시로 NER에 대해 좀 더 살펴보겠습니다.
NER을 활용하면 해당 단어가 어떤 카테고리인지에 따라, 관련 데이터를 보다 정교하게 분석하여 다른 검색 결과를 보여줄 수 있게 되는데요. 만약 누군가 줌닷컴에서 ‘수지’를 검색한다고 했을 때, NER은 ‘수지’가 어떤 역할로 쓰였는지를 분석하여 특정 뉴스를 인명으로 분류해 연예란에 넣을지, 지명으로 분류해 경제란에 넣을지를 결정하게 됩니다.
2. 포털에서의 NER 구현 방법
지금부터는 동일한 예시 문장을 가지고, 줌닷컴에 이 NER을 어떻게 구현했는지 그 방법을 살펴보겠습니다. 그림3과 같은 구조로 NER을 구현할 수 있었는데요. 예시 문장이 한 그림 상에 다 들어가지 않아 부득이하게 뒷 부분을 자르게 된 점 양해 부탁드립니다.
사실 그림으로 보면 큰 내용은 없어 보이지만, 각 항목들이 낯선 영어여서 더 읽기 싫어지시죠? NER을 처음 보시는 분들도 쉽게 이해하실 수 있도록 간단히 설명을 드려 보겠습니다.
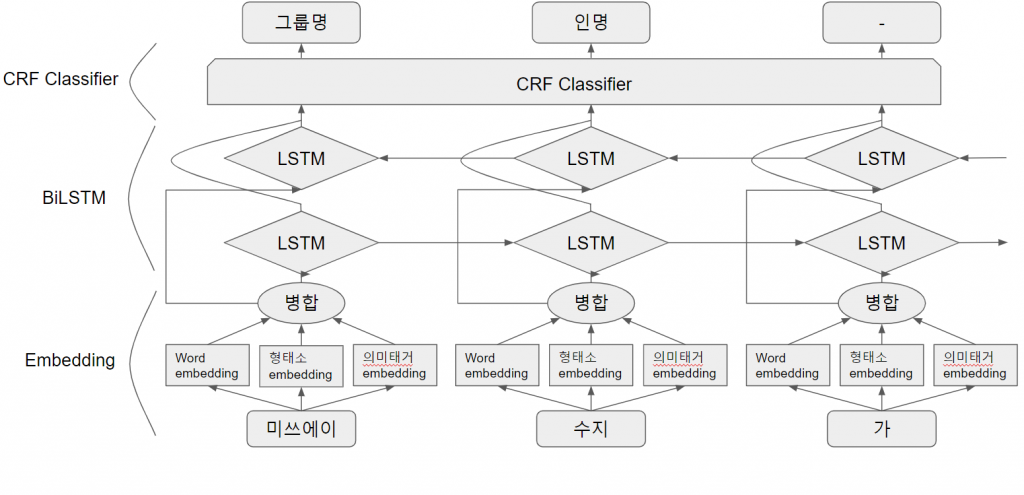
NER을 하기 위해서는 먼저 컴퓨터에게 제일 아래 위치한 예시 문장에 ‘개체명을 붙여야 한다’고 명령을 내려야 하는데요. 컴퓨터는 해당 단어들을 자기가 쉽게 알아볼 수 있도록 ‘임베딩(Embedding)’이란 것으로 변환을 하게 됩니다. 이때, 임베딩이라는 것은 벡터(Vector), 즉 특정한 길이를 가진 숫자들의 나열입니다.
예를들면 ‘미쓰에이’라는 단어는 그림4에서와 같이 (0, 0, 1, 1, 1)이라는 숫자의 나열로 변환될 수 있는데요. 이는 길이가 5인 벡터로 볼 수 있습니다. 본래는 길이를 50~200정도로 크게 설정하고 벡터의 각 숫자도 0.76, -0.93같이 -1~1 사이의 유리수로 설정하지만 간단한 예시를 위해 짧게 0과 1로 잡아보겠습니다.

이를 전체적인 맥락에서 보면, 전체 단어의 변환이 끝나고 컴퓨터는 변환된 임베딩값을 통해 “(0, 0, 1, 1, 1), (0, 0, 1, 1, 0), (0, 1, 1, 0, 0), …”이 들어왔으니 “미쓰에이, 수지, 가, …”라는걸 번역하라고 한거구나! 라고 이해할 수 있습니다.
다만, 임베딩 과정에서는 적당한 0과 1의 부호로 바꾸는게 아니라, 유사한 단어일수록 유사한 벡터로 변환해서 ‘여러 단어들이 서로 비슷하게 의미를 가지는구나’ 하는 것까지 컴퓨터에 이해시키도록 벡터를 만드는 작업이 중요합니다. 예를 들면, ‘미쓰에이’가 (0, 0, 1, 1, 1)이라면 이와 유사한 ‘수지’는 (0, 0, 1, 1, 0)으로 만들고, 거리가 먼 ‘줌인터넷’은 (1, 1, 0, 1, 0)으로 변환하는 식입니다.
컴퓨터는 이 임베딩된 벡터가 어떤 의미를 가지고 있는지 두뇌풀가동을 시전하는데요. (컴퓨터니까 CPU풀가동이라고 해야 되겠네요) 이 CPU를 풀가동하는 부분이 바로 ‘BiLSTM 과정’입니다. 여기서 ‘LSTM’은 컴퓨터가 문장을 이해하는 과정인데요. 문장을 앞에서부터 한 번 읽으면서 이해하고, 뒤에서부터 다시 읽으면서 자세히 이해해보기 때문에 ‘Bidirectional(양방향의)-LSTM’이라 하는데, 이를 약자로 BiLSTM이라고 합니다.
하지만, 이 결과값도 컴퓨터가 출력한 값이기 때문에 벡터로 구성되어 있어 바로 우리가 알아보기는 어려운데요. 컴퓨터가 미쓰에이를 보고 이 단어의 개체명이 (0, 0, 1, 1, 1)이라고 알려줘도, 우리는 알아볼 수 없기 때문에 벡터를 한글로 변환하는 필터 ‘CRF Classifier’가 필요합니다. 이 분류기를 거치고 나면 이제 “처음 들어온 ‘미쓰에이’라는 단어가 ‘그룹명’이라는 개체명을 가지는구나”라고 이해할 수 있게 되는데요!
3. 구체적인 NER 구현 과정
그러면 이제 전반적인 NER 구현 과정을 살펴 보았으니, 그림3에서 표현된 각 부분들을 제대로 살펴보겠습니다. (AI가 어떻게 동작하는지까지는 궁금하지 않다 하시는 분들은 대충 훑어 읽으셔도 무방한 부분이니, 숫자와 수식이 나온다고 해서 머리를 쥐어싸매지 않아도 괜찮아요!)
1) Embedding
저희가 개발한 NER에는 세가지의 embedding이 사용됩니다. 이는 단어별로 word embedding과 형태소 embedding, 그리고 의미태깅 embedding입니다. 이 세가지 embedding을 처음 그림에서처럼 합해서 하나의 vector로 만든 후에 이것을 BiLSTM의 입력값으로 사용합니다.
단어에 쓰이는 word embedding은 흔히 쓰이는 word2vector보다 다소 생소할 수 있는 fasttext를 사용했습니다. 처음에는 word2vector의 사용도 고려했으나, 내부적으로 테스트를 거친 결과 정확도에 있어 fasttext가 더 좋은 결과를 나타내어 이를 사용하게 되었습니다. 형태소 embedding은 각 형태소별로 fpre-trained된 embedding값을 적용하였습니다. 의미태깅 embedding은 처음 들어볼 수도 있는 단어인데요. 회사 내부에서 사용하는 사전을 참조하여 해당 단어가 사전에 있을 경우 특정한 vector값을 적용하는 방식입니다.
2) BiLSTM
BiLSTM에 대한 설명을 위해, LSTM을 먼저 간략히 설명하고 넘어가겠습니다. LSTM은 딥러닝 과정 중에 잊혀지는 과거 정보를 기억하면서 학습을 진행하는 RNN의 일종으로, 과거 정보 중 어떤 것을 잊고, 어떤 것을 기억할지를 정하는 gate라는 것이 도입된 학습 방법입니다. 다만, 기존의 LSTM은 단방향으로 진행되기 때문에 학습이 진행될수록 앞에서 입력된 정보의 영향력이 약해지는 경향이 있습니다. 이 점을 보완하기 위해 뒤에서 앞으로 진행하는 LSTM을 추가하여 엮은 BiLSTM을 활용했습니다.
3) CRF Classifier
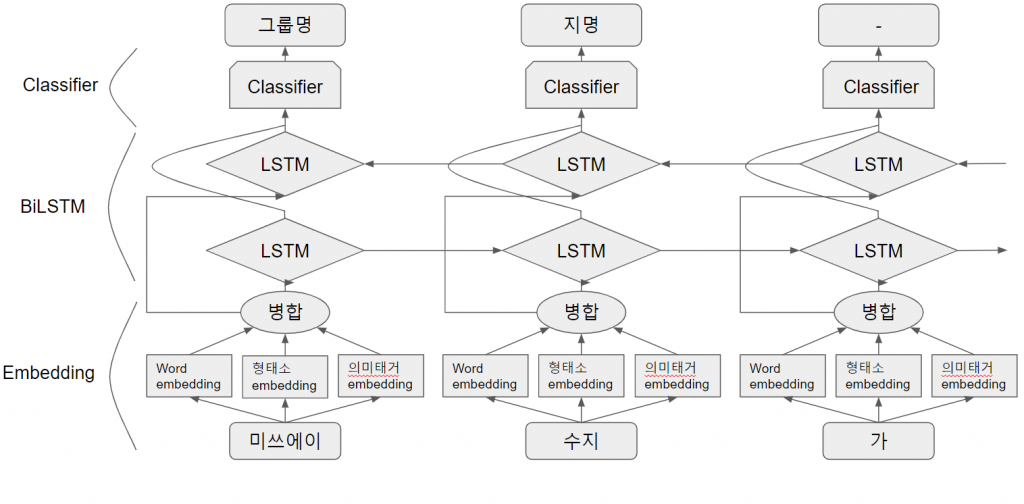
CRF란 Conditional Random Field의 약자로서 통계적 모델링 기법의 일종입니다. CRF를 적용하지 않은 일반적인 모델의 경우에서 LSTM의 출력을 분류한다면 그림5와 같은 결과가 도출될 수 있습니다. 그림5를 보면, 앞뒤 문맥을 고려하지 않아 ‘수지’를 미쓰에이 수지가 아닌, 흔히 쓰이는 지명으로 분류해버렸는데요.
CRF는 여러 출력에 대해 각각 예측값을 정하는게 아니라 출력들 전체의 예측값을 정해줌으로써 이러한 상황을 해결하기 좋은 기법입니다. NER같은 경우에도 각 단어가 앞뒤 문맥에 따라 다른 의미를 가지게 되므로, 같은 단어라도 다른 개체명을 붙일 수 있게 되어 보다 정확한 결과를 도출할 수 있게 됩니다.
지금까지 저희가 개발한 NER에 대해 간단히 알아보고 넘어왔는데, 어떠신가요?
사실 각 모델들에서 동작하는 방법을 하나하나 살펴본다면 좀 더 어려운 수식과 절차를 거쳐 유사논문이 될 것 같아, 어렵고 복잡한 부분은 제외하고 개념만 자세히 살펴보았는데요! 기회가 된다면 다음 시간에는 오늘 간략하게 넘어간 부분들도 자세히 다뤄보겠습니다.
앞으로도 줌인터넷의 연구와 줌닷컴에 많은 관심과 응원 부탁드립니다. 감사합니다.
또 다른 검색 서비스 연구 내용이 궁금하다면?