안녕하세요, AI PLUS Tech Blog입니다. 오늘은 AI 아나운서 제작에 사용된 기술 중 딥러닝 생성모델 관련한 내용을 소개하려 합니다.
과거 산업 현장에서 딥러닝이 주로 성과를 내는 부분은 인식(recognize) 분야였습니다. 딥러닝이 산업계에 쓰이기 시작한 초창기에는 구글 번역 등 아주 일부 영역만 딥러닝 생성(generation)모델이 채택되었는데요, 최근 딥러닝 모델의 음성 합성(speech synthesis) 및 영상 생성 품질은 방송 제작에 쓰일 수 있을 정도로 향상되었고 그 활용 범위도 넓어졌습니다.
실제로 이스트소프트 AI 연구소에서는 텍스트로부터 음성을 생성하는 TTS(Text To Speech) 기술과 음성으로부터 얼굴을 생성하는 STF(Speech To Face) 기술을 사용해 AI 아나운서를 제작했고, 생성된 AI 아나운서가 지난 4월 15일에 YTN 특집 뉴스 방송의 일부를 진행한 바 있습니다. (AI 아나운서 개발기 보러 가기 : https://blog.estsoft.co.kr/782)
그럼 지금부터 생성모델에 입문하시는 분들에게 도움이 될 수 있도록, 생성모델이 무엇이지 그리고 생성모델에서 잠재 벡터는 어떤 역할을 하는지에 대해 소개하겠습니다.
1. 생성모델의 문제 개요
기계학습(machine learning)모델은 크게 인식모델과 생성모델로 구분할 수 있습니다. 인식모델은 데이터를 분류(classify)하거나 군집화(clustering)하는데 주로 사용되는데 보통 고차원 원본 데이터를 저차원 라벨 데이터로 변환합니다.
그 예로는 음성 데이터를 텍스트 데이터로 변환하는 음성 인식(Speech To Text)모델이나 영상 내의 문자 영역을 텍스트로 변환하는 문자인식(Scene Text Recognition) 모델이 있습니다. 모두 일정한 구조를 갖춘(structured) 고차원 원본 데이터를 저차원의 라벨 데이터로 변환한다는 특징이 있습니다.
반면, 주어진 텍스트로부터 음성을 생성해 내는 음성 합성(Text To Speech)의 경우, 입력 데이터에 비해 출력 데이터의 차원이 훨씬 고차원입니다. 음성 합성 모델이나 손글씨 생성모델 등과 같이 특정 조건에 부합하는 고차원 데이터를 생성하는 경우 외에도, 무작위 얼굴 생성모델과 같이 명시적인 조건 없이 데이터를 생성하는 경우도 있습니다.
실제 활용 예와는 다르게 조건 없이 무작위로 생성하는 경우를 생성모델 연구의 기본 세팅으로 설정하는 것이 생성모델 분야를 처음 공부할 때 이해하기 어려운 부분일 수 있습니다.
그 이유는 생성한 결과물이 얼마나 충분한 다양성을 가질 수 있느냐가 생성모델의 주요 관심사이기 때문입니다. ‘웃는 모습의 강아지 얼굴’에 대응되는 이미지는 무수히 많습니다. 사람이 그림을 그릴 경우, 특히 전문적으로 그림을 그리는 화가는 ‘웃는 모습의 강아지 얼굴’에 대응되는 무수히 많은 다른 그림을 그릴 수 있을 것입니다.
이처럼 생성모델은 동일한 조건에서도 자연스러운 데이터를 무수히 생성해 낼 수 있어야 합니다. 이 부분이 생성모델에서 해결하기 가장 어려운 부분이기 때문에, 생성 알고리즘 자체에 관한 연구에서는 입력 조건 부분을 생략하고 학습 데이터와 유사한 무작위 데이터를 얼마나 다양하게 생성할 수 있는가에 집중합니다.
반면, 인식 문제 해결을 위한 분류 모델은 해당 데이터가 속한 그룹을 결정하는 문제에 초점을 맞추기 때문에, 그룹을 결정하는데 있어서 우선순위가 낮다고 판단되는 정보는 무시되는 방향으로 학습이 진행됩니다.
가령, 강아지와 물고기를 구분하도록 학습이 된 인식모델의 경우, ‘돼지’ 이미지가 입력되면 매우 높은 확률로 강아지라고 판단합니다.
산업 현장에서는 이와 같이 학습 과정에서 보지 못한 데이터에 대해, 시스템이 스스로 걸러 낼 수 있는 장치가 필수적으로 요구됩니다. 메트릭 러닝이나 메타 러닝 등 인식 모델 연구에서도 Open-Set 문제나 OOD(Out-Of-Distribution) 문제를 공략하기 위한 다양한 기법들이 개발되고 있으나, 생성모델은 보다 직접적으로 이 문제를 접근합니다.
제대로 학습된 생성모델은 그럴듯한 강아지와 그럴듯한 물고기 이미지를 생성하도록 학습되기 때문에, 학습 데이터에 존재하지 않는 ‘돼지’ 이미지를 생성하지 않습니다. 그럴듯한 강아지 이미지 생성을 위해서, 생성모델은 인식모델이 간과하는 상세한 부분까지 파악해야 합니다. 인식모델은 그룹화에 있어서 중요성이 높은 특징값 파악에만 집중하는 반면, 생성모델은 그럴듯한 데이터 생성을 위해 데이터의 상세한 부분까지 모두 파악해야 합니다. 따라서, 사람이 수동으로 라벨링한 정보를 주로 활용하는 인식모델 기법을 넘어서는 다양한 기술이 요구됩니다.
2. 잠재 벡터를 이용한 생성
2-1. 잠재 벡터 도입
‘사람 얼굴’ 이미지에 대한 연구는 컴퓨터 비전 분야에서 중요하게 다뤄지기 때문에, 생성모델은 얼굴 데이터셋을 통해 그 성능을 보여주는 경우가 많습니다.
얼굴 데이터에 대해 현재 가장 높은 품질을 보여 주는 생성모델은 엔비디아(NVIDIA)의 스타일간(sylegan) 계열 모델입니다. 스타일간 모델은 1024x1024 해상도를 갖는 70,000여 장의 일반인 얼굴 이미지로 구성된 ‘Flickr-Face-HQ (FFHQ)’ 데이터셋으로 학습을 시켰습니다.
그럴듯한 얼굴 이미지가 되기 위해서는 얼굴 생김새 뿐만 아니라, 상황의 일관성도 중요합니다. 그림자 방향, 머리카락 흩날림 등이 모두 일관성이 있어야 합니다. 눈 색깔과 크기, 고개 돌림 각도, 조명 강도 및 방향, 바람의 세기와 방향등 여러 요인이 얼굴 이미지 생성에 관여하지만, 그 모든 것을 수동으로 라벨링 하기는 불가능에 가깝습니다.
딥러닝 생성 모델에서는 이와 같은 독립 변수들을 사람이 직접 라벨링하지 않고, 모델 스스로 찾아가게 하는 전략을 사용합니다. 바람의 방향과 세기, 빛의 방향과 세기 등과 같이 이미지에 영향을 미치는 요소를 사람이 직접 라벨링 할 수 없기 때문에, 생성모델은 기본적으로 지도 학습 형태를 취하지 않습니다.
학습에 사용되는 이미지는 실제로 존재하는 사물과 상황에 대한 포착 이라고 보고 실제로 존재하는 사물과 상황의 모습을 결정하는 조건들을 ‘잠재 변수(latent variable)’로 모델링 합니다.
얼굴이 그려지기 위해서는 성별, 나이, 인종, 머리스타일, 피부색, 얼굴 표정 등등 그 사람의 외양을 결정하는 요인뿐만 아니라, 그림이 그려지는 순간(또는 사진이 찍혀질 때)의 주위 배경, 얼굴각도 및 거리, 바람, 빛 등 주변 상황이 종합적으로 관여하게 됩니다. 일반적으로 생성모델에서는 이런 조건을 미리 상정하지 않고, 모델이 스스로 데이터 학습을 통해 찾아내길 기대합니다.
스타일간에서의 잠재 변수는 총 512개 입니다. 독립적인 잠재 변수들의 쌍을 ‘잠재 벡터(latent vector)’라고 부릅니다. 512 차원의 잠재 벡터에 의해 생성되는 이미지는 1024×1024×3 = 3,145,728개의 픽셀값을 가집니다.
 <그림1. 5 StyleGAN 으로 생성한 1024x1024 해상도 이미지>
<그림1. 5 StyleGAN 으로 생성한 1024x1024 해상도 이미지>
인식모델에서도 표현 학습(representation learning) 영역의 잠재 변수 개념을 다루지만, 생성모델에서는 의미 있는 잠재 벡터 생성이 쉬워야 한다는 제약이 강조됩니다. 보통 인식모델에서의 잠재 벡터는 입력 데이터를 변환하여 생성하는 반면, 생성모델에서는 입력 데이터와는 독립적으로 잠재 벡터를 쉽게 생성할 수 있어야 합니다.
예컨데, ‘안경을 쓴 얼굴’을 그리는 경우 안경을 쓰고 있다는 조건이 입력으로 주어졌을 경우, 안경 착용 여부와는 독립적으로 피부색, 빛의 강약, 바람 세기 등의 세세한 부분을 제어할 수 있는 다양한 잠재 변수값을 쉽게 생성할 수 있어야 합니다.
의미 있는 잠재 벡터값을 쉽게 생성하기 위해서는 잠재 벡터의 각 성분간 상관관계가 없도록 학습이 되어야 합니다. 얼굴을 그리기 위해 성별과 바람의 방향을 잠재 변수에서 선택하는 경우를 생각해 봤을 때, ‘여성이라면 바람의 방향은 높은 확률로 왼쪽이어야 한다’와 같은 두 잠재 변수 사이에 상관관계가 있다면 잠재 벡터 선택이 어렵습니다.
잠재 벡터의 독립적인 개별 잠재 변수값 역시 각각 생성하기 쉬워야 합니다. 얼굴 생성모델의 잠재 벡터 중 얼굴 방향에 관여하는 잠재 변수를 예시로 설명하겠습니다.
일반적으로 FFHQ 학습 데이터에는 서 있는 자세로 카메라 방향을 바라보는 경우가 대부분이고, 측면을 응시하는 경우도 종종 있으나 전처리를 거쳐 정제된 데이터이기 때문에 누워서 하늘을 바라보거나 엎드려있는 경우는 없습니다. 얼굴 방향을 나타내는 잠재 변수값을 고를 때, 이러한 데이터의 실제 분포를 직접 고려해서 값의 범위와 분포를 정해야 한다면 잠재 변수 생성이 어렵다고 볼 수 있습니다. 따라서 잠재 변수 생성은 정규 분포나 균등 분포와 같이 손쉬운 추출 (sampling)을 위해, 알려진 방식을 따르도록 모델링 합니다.
2-2. 의미적인 구조를 갖춘 데이터로 변환하기
정규 분포나 균등 분포에서 독립적으로 개별적인 잠재 변수를 뽑아서 잠재 벡터를 생성한 후 생성모델이 해야되는 일은 이렇게 대응되는 실제 데이터로 변환하는 작업입니다.
잠재 벡터의 각 구성 성분은 독립인 반면, 우리가 생성해야되는 최종 데이터의 각 구성 요소 사이에는 강한 상관관계가 있습니다. 머릿결, 바람의 방향, 머리카락 색깔 등이 일관되어야 합니다. 즉, 픽셀들이 취할 수 있는 값은 주위값들에 의미적인 영향을 받아야 합니다.
여러 색으로 염색을 한 머리카락의 경우에도, 허용되는 다양성과 패턴이 존재하게 됩니다. 왼쪽 눈과 오른쪽 눈 사이에도 강한 연관성이 존재합니다. 이와같이 데이터 벡터의 각 구성 요소가 서로 ‘의미 있는 상관관계’를 가진 데이터를 구조를 갖춘(structured) 데이터라고 표현합니다. 생성모델이 ‘그럴듯한 이미지를 그린다’ , ‘자연스런 음성을 생성한다’라는 뜻은 데이터의 구조를 잘 포착했다는 것을 의미합니다.
즉, 학습데이터를 통해 생성모델이 배우기를 기대하는 것은 아래 두 가지입니다. 1) 의미 있는 잠재 벡터를 쉽게 생성하도록 잠재 벡터 공간 구성하기 2) 잠재 벡터에 대응되는 자연스러운 데이터를 생성하는 변환 규칙 찾기
2-1-1. 부호와(coding) 와 오토 인코더
균등 분포나 정규 분포에서 서로 독립적으로 추출 (sampling)한 잠재 변수로 구성된 잠재 벡터를 변환해, 구조를 갖는 데이터를 생성하는 것을 일반적으로 ‘디코딩(decoding, 역부호화)’이라고 표현합니다.
부호(coding)는 정보이론이나 통신이론에서 등장하는 개념입니다. 원본 데이터의 표현법을 목적에 맞게 바꾸는 과정을 인코딩 (encoding)이라 부르고, 이렇게 부호화된 데이터를 다시 원본 데이터의 표현법으로 복원하는 과정을 디코딩(decoding)이라고 부릅니다.
인코딩과 디코딩은 오류가 발생하기 쉬운 통신로나 저장 매체에서 오류 복원이 용이하도록 하거나, 통신비용, 저장비용을 절감하기 위해 압축된 표현을 써서 데이터의 용량을 줄이려는 경우에 주로 사용됩니다. 목적에 맞는 효율적인 인코딩 방법을 찾는 문제는 정보 기술 분야에서 꾸준히 연구되는 중요한 분야입니다.
인코딩 방법은 전통적으로는 추상 대수학(abstract algebra), 암호학(cryptography) 등에서 엄밀한 수학적 분석을 통해 기본 기술이 발전되고, 이미지나 음성 분야에서 각 데이터의 특성에 맞춘 공학적인 기법을 추가해 개발되고 있습니다. 그 동안 인코딩 이론들은 데이터의 의미적인(semantic) 부분 보다는 데이터 값의 빈도, 즉, 통계적인 생김새(syntax)에 기반을 두어 발전해왔습니다.
이에 반해 딥러닝 분야에서는 의미적인 부분을 포착하는 인코딩 방법을 찾는데 초점이 맞춰집니다. 또한 인코딩 방법을 찾는 행위 역시 수학적인 고려 등 사람의 수학적 지능을 요구하지 않고, 일반적인 뉴럴 네트워크 구조와 학습 알고리즘을 이용해 변환 함수를 찾게 됩니다.
이처럼 일반적인 딥러닝 학습 방법 외 별도의 알고리즘을 고안하지 않기 때문에, 자동으로 찾아진다는 의미에서 오토 인코더(auto-encoder)라고 부릅니다.
오토 인코더는 생성모델이라고 볼 수 없지만, 생성모델의 학습 과정과 개념 이해를 위해서는 오토 인코더의 구조와 개념을 익히는 것이 중요합니다. 오토 인코더가 생성하는 인코딩 벡터는 잠재 벡터에 대응됩니다. 하지만 일반적인 오토 인코더는 생성모델을 염두하지 않기 때문에, 잠재 벡터 추출(sampling)이 쉬운 분포를 따라야 한다는 제약이 없습니다.
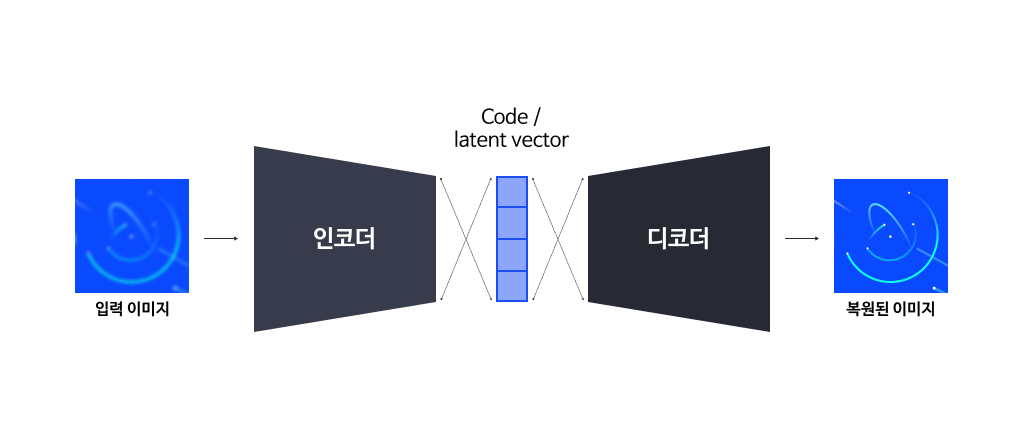 <그림1. 오토 인코더>
<그림1. 오토 인코더>
2-2-2. 잠재 벡터로부터 데이터를 생성하는 여러 기법
AI 뉴스 앵커(아나운서) 제작에는 GAN과 flow-based 계열의 생성모델을 사용하였습니다.
GAN(Generative Adversarial Network) 계열에서는 생성 네트워크와 판단 네트워크를 따로두고, 생성 네트워크는 디코딩 함수만 학습합니다. 데이터 생성을 위해 무작위로 정규 분포에서 잠재 벡터를 생성하고, 생성 네트워크는 잠재 벡터에 대응되는 데이터를 생성하게 합니다. 또한, 생성된 데이터가 실제 데이터인지 실제 데이터가 아니라 생성된 데이터인지를 구분하는 판단(discriminator) 네트워크를 동시에 경쟁적으로 학습시킵니다. 이때 판단 네트워크를 암시적인(implicit) 인코더로 볼 수 있습니다.
이러한 방식은 인코더와 디코더 간의 제약이 없어 다양한 컴퓨터 비전 분야의 기법들을 채용하기 쉬워 일찍부터 활발한 연구가 이루어졌기 때문에, 생성모델 계열에서 가장 높은 품질을 보여주고 있습니다. 하지만 학습을 안정적으로 시키기 위한 세팅값을 찾기 어렵다는 단점이 있습니다.
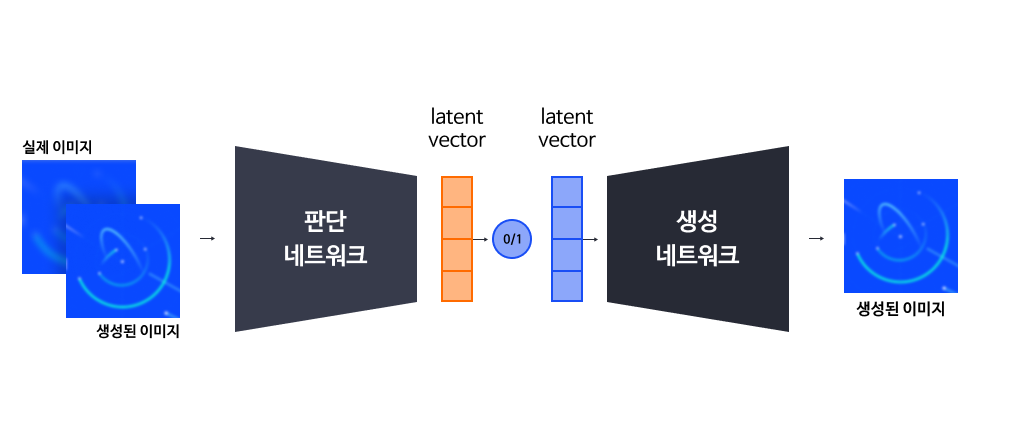 <그림 3. GAN: Generative Adversarial Network >
<그림 3. GAN: Generative Adversarial Network >
Flow-based 계열에서는 인코더와 디코더가 정확히 역함수 관계를 갖습니다.
입력 데이터를 역변환이 존재하는 여러 변환을 거쳐, 정규 분포(normal distribution)를 따르는 잠재 벡터값을 갖도록 학습하는 기법을 ‘Normalizing flow’라고 합니다. 이 기법은 학습 단계에서는 이미지를 생성하지 않고, 잠재 벡터만 생성한다는 특징이 있습니다. 네트워크를 통과시켜 나온 잠재 벡터를 정규 분포로 유도하는 목적 함수(object function, loss function)를 이용해 학습합니다.
기존의 뉴럴 네트워크 구성 방식은 역변환 가능성을 염두에 두지 않았지만 Normalizing flow 연구에서는 역변환이 가능하면서 잠재 벡터가 정규 분포를 따르도록 학습이 가능한 구조를 찾는데 초점을 맞추기 때문에, 일반적인 CNN 모듈을 사용하지 못하고 특정한 제약이 있는 모듈들로 네트워크가 구성됩니다.
GAN 모델에서는 잠재 벡터 차원이 데이터 차원보다 훨씬 적지만, flow-based 모델에서는 역변환이 가능해야 하기 때문에 잠재 벡터의 차원은 입력 데이터의 차원과 동일합니다. 학습 방향, 즉, 데이터로부터 normal 분포를 갖는 잠재 변수로의 방향을 forward flow 방향이라고 하고, 역방향을 inverse flow 방향이라고 합니다. 학습이 완료된 모델을 이용해 데이터를 생성할 때는 inverse flow 방향의 연산만 수행하게 됩니다.
 <그림 4. Flow based Model>
<그림 4. Flow based Model>
3. 결론
이번 포스팅에서는 생성 모델이 해결해야되는 문제점과 해결책을 위해 도입된 잠재 벡터에 대해서 살펴보았습니다.
구체적으로는 인식모델과 생성모델에서 잠재 벡터의 역할과 차이점을 살펴봄으로써 인식모델이 겪는 OOD(Out of Distribution) 문제 등이 생성모델과 어떻게 연결되지와 오토 인코더 구조 및 개념을 통해 생성 모델의 특징을 파악해 보았습니다.
생성 분야에 입문하는 분들에게 이번 포스팅이 유익한 정보가 되기를 기대합니다.