안녕하세요. AI PLUS Tech Blog입니다. 이스트소프트에서는 인공지능 생성 모델을 활용한 버추얼 휴먼 사업을 진행하고 있습니다. 버추얼휴먼 연구에서는 사람의 목소리를 세밀하게 다루는 기술이 주요하게 부각됩니다.
특히 이스트소프트에서는 상황에 맞는 자연스러운 음성 생성 연구에 주력하고 있습니다. 새로운 소식 전달을 위한 뉴스 앵커 음성, 전문 지식 전달을 위한 강의 음성, 인터뷰를 위한 자연스러운 방화 음성등은 모두 제각각 용도에 따른 특색이 있기 때문인데요.
생성 모델 개발을 위한 전처리 작업 등을 위해서는 일반적으로 인식 모델 활용 기술이나 도메인 특화된 신호 처리 기술이 필요합니다. 즉, 버추얼 휴먼의 음성 생성을 위해서는 생성 연구 뿐만 아니라 음성 신호에 대한 인식 및 처리 기술 고도화가 필요한 것인데요. 이스트소프트에서는 해당 기술의 수준을 경쟁할 수 있는 자리인 인공지능 챌린지에 참여하여 좋은 성과를 거두었습니다. 바로, 과학기술정보통신부가 주최한 <2021 인공지능 그랜드 챌린지> 3차 대회에서 1위를 수상한 것입니다.
오늘은 이 대회의 Task 2에서 사용한 음성 신호 처리에 대한 솔루션을 소개하도록 하겠습니다.
1. 문제 정의
<2021 인공지능 그랜드 챌린지> 3차 대회는 Task 1~4로 이루어졌습니다. 이 중 Task 2는 재난상황 중 드론을 통해 촬영된 건물 내 영상·사진 데이터를 활용해 구조 대상의 고립 위치를 파악하고, 구조자 수와 성별·연령을 구분하고, 상태를 파악하는 문제였습니다.

2. 데이터 분석 및 풀이전략
대회 주최측에서 제공한 샘플 데이터를 분석해보니 드론의 프로펠러 소리가 크기 때문에 Voice Activity Detection, Denoising, voice enhancement 기술이 제대로 동작하지 않았습니다.
큰 잡음이 있는 환경에서 미세한 차이를 포착해야 하므로 kaggle 등 과거 유사 챌린지의 솔루션을 참고하여 ‘wav를 이미지로 변환한 후 이미지 분류 문제로 풀기’로 전략을 세웠습니다. 이미지 분류의 경우 의료 데이터나 외계 신호 시각화 데이터 등의 특수한 분야에서도 미묘한 차이를 딥러닝 모델이 정확히 구분해 낼 수 있었습니다.
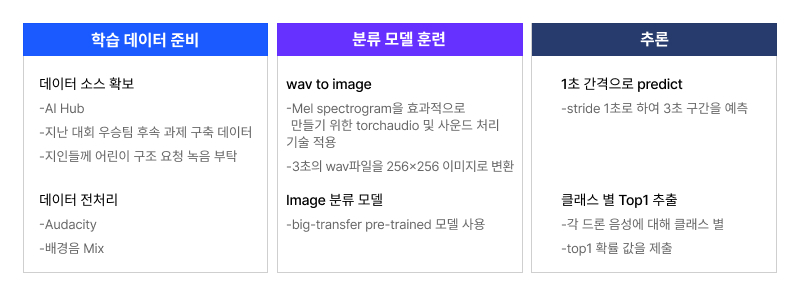
주최측의 평가 메트릭 분석 결과 recall을 올리기보다 precision 값이 높아야 하기 때문에 제출하는 예측 개수를 최소화하고 다음과 같은 풀이 전략을 도출했습니다.
- 3초 구간의 음성을 [남성,여성,어린이,배경음]으로 분류하는 분류 모델 작성
- 1초 단위의 stride로 sliding window를 적용하여 각 구간 분류
- 각 드론당 남성, 여성, 어린이 클래스에 대해 top1 예측 결과를 제출 즉, 5개 영상 *3개 드론* 3개 클래스 = 45개 제출
학습 데이터 마련등을 포함한 전체 워크 플로우는 <그림2>와 같습니다.
3. 학습 데이터 마련 - AI Hub
이번 대회에서도 지난 챌린지와 동일하게 AI Hub (https://aihub.or.kr/) 의 데이터를 학습 데이터로 활용했습니다.
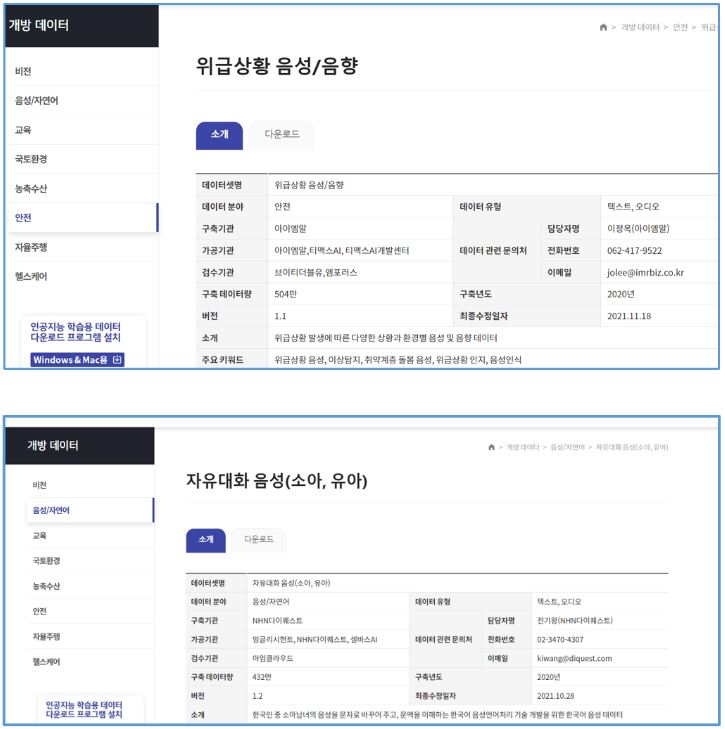
먼저 ‘위급상황 음성/음향’ 데이터를 다운받아 대회 샘플과 유사한 톤과 내용을 담은 음성 데이터만 추려서 사용했습니다. “살려 주세요”, “거기 누구 없어요”, “불이야” 등의 구조 요청이 풍부하게 있었지만, 어린이 음성이 없었습니다. 따라서 ‘자유대화 음성(소아, 유아) 카테고리에서 다양한 어린이 음성을 확보해서 사용하는 것으로 음성 데이터를 대체하였습니다.
4. 학습 데이터 마련 - 이전 입상팀 후속 연구 산출물 데이터
<2019 AI 그랜드 챌린지>에서 입상한 팀의 후속 연구 산출물 데이터도 활용하였습니다. 19년 대회에서도 인공지능 부분 Track3에서 드론으로 취득된 음향 내 구조 요청 소리를 판별하고 방향을 추론하는 문제가 있었는데요. 후속 연구 결과물로 드론 환경에서 취득된 음성 데이터를 github에 공개해 놓았고 이 중에서 음향 데이터만 추려서 사용하였습니다. 동일 구간에서 여러 사람이 동시에 발화되는 데이터 등 이번 대회에서 출제되지 않을 패턴의 데이터들은 직접 들어보고 제외하였습니다.
5. 학습 데이터 마련 - 음성 실제 녹음
어린이들이 대회 샘플 데이터와 유사한 톤과 내용으로 구조 요청 보내는 데이터가 부족했기 때문에 대회 참가팀 가족이나 지인 가족들에게 요청하여 다양한 연령대의 유아 및 어린이들의 구조 요청 음성을 확보했습니다. 직접 녹음한 데이터는 훈련 데이터로는 사용하지 않고 평가 데이터로만 사용했습니다.
6. 학습 데이터 전처리
먼저 음향 편집기 Audacity(https://www.audacityteam.org/) 툴의 ‘효과’ 메뉴 항목에 있는 다양한 효과들을 이용하여 배경음과 구조음성을 1차로 증폭처리 하였습니다.
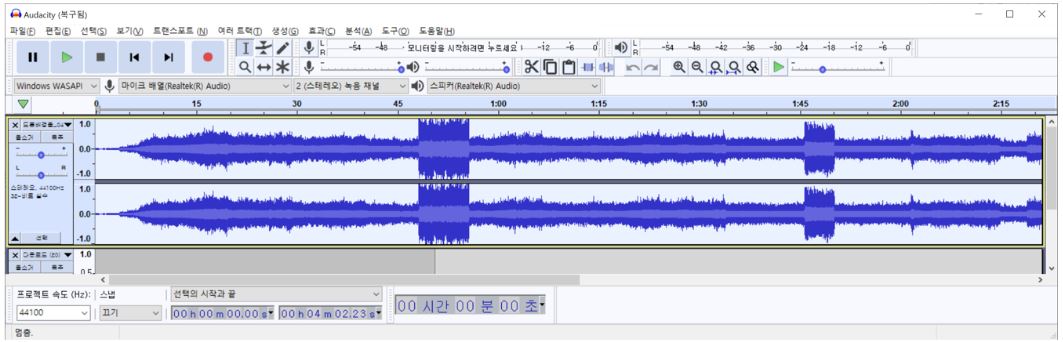
다음으로는 python 스크립트를 이용해 드론 배경음과 사람의 구조 요청 음성을 랜덤하게 섞어서 데이터양을 증폭시켰습니다. 구조 요청 음성과 드론 배경음의 볼륨 크기 비율이 대회 샘플과 유사해지도록 볼륨 비율을 주의해서 튜닝했습니다.
<그림7> 에서 사람 구조요청과 배경음을 합성하는 전체 소스 코드를 확인할 수 있습니다.
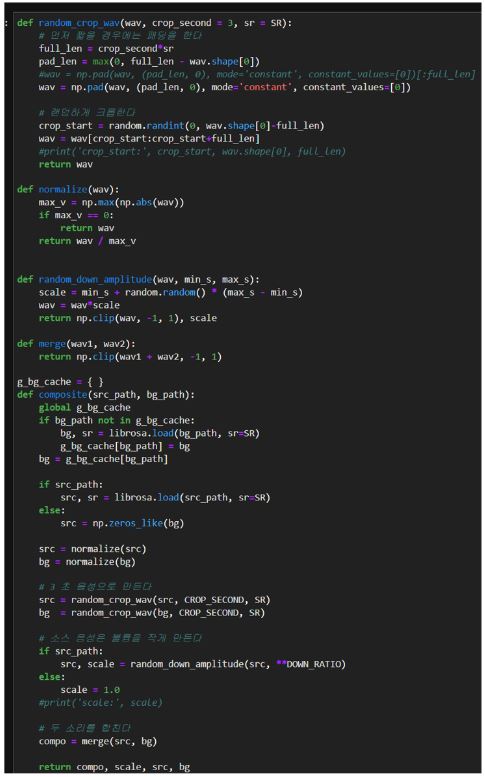
7. 데이터 전처리 및 딥러닝 모델
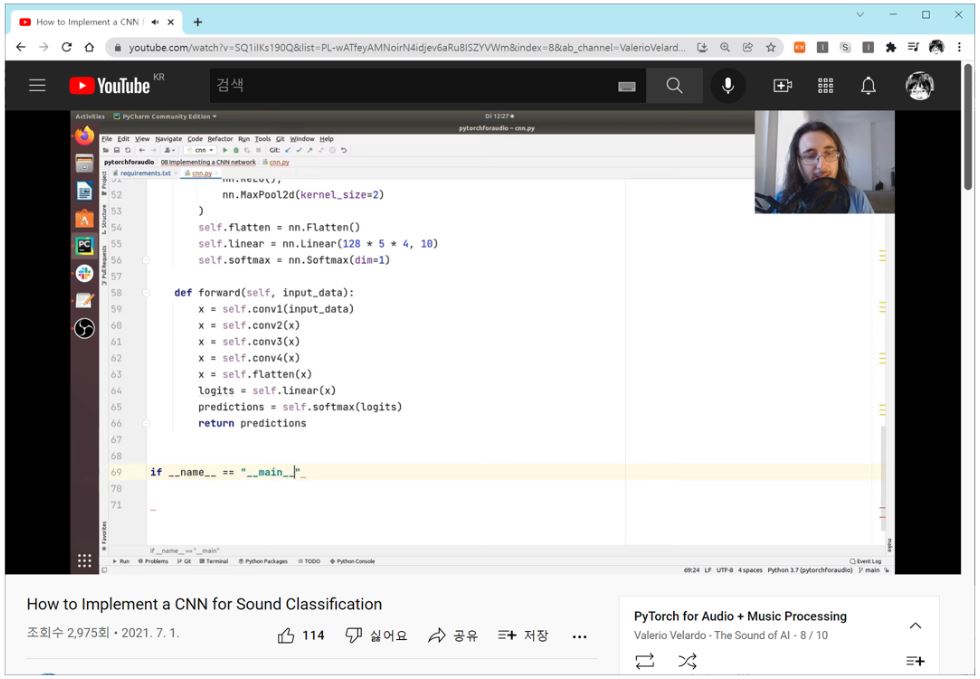
유튜브 채널 “Valerio Velardo – The Sound of AI” 의 PyTorch for Audio + Music Processing 의 내용을 참고하여 3초 길이 wav 파일을 256x256 해상도의 mel spectrogram 이미지 파일로 변환하였습니다.
동영상을 참고하면 torchaudio 모듈을 활용하여 손쉽게 변환하는 법을 배울 수 있습니다.
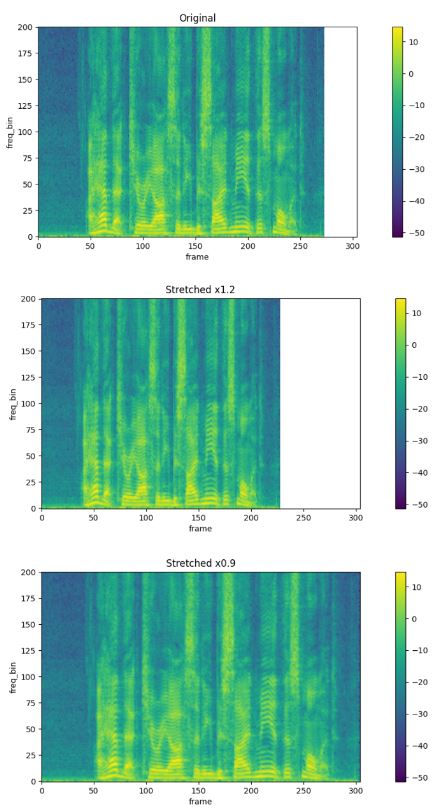
또한 pytroch 공식 홈페이지인 https://pytorch.org/tutorials/beginner/audio_preprocessing_tutorial.html#specaugment 확인할 수 있듯이 torchaudio 패키지 내에는 음성 데이터를 시각화한 spectrogram 데이터에 대해서 수행할 수 있는 효과적인 augment 방법론이 이미 구현되어 있습니다.
위 동영상에서는 간략한 CNN 모델을 구성하여 음향 분류 모델을 만들었지만 저희는 구글에서 발표한 big-transfer 모델을 사용했습니다. big-transfer 모델에 대한 보다 자세한 내용은 공식 페이지인 https://github.com/google-research/big_transfer 에서 확인할 수 있습니다.
big-transfer 모델은 다양한 대규모 데이터로 pre-trained 되어 의료 데이터 등 데이터셋이 적은 테스크에서도 transfer learning을 통해 좋은 결과를 내는 모델입니다.
8. 결과
대회 문제에 대한 심도 있는 분석, AI Hub 데이터의 적극적인 활용, 대회 규격을 고려한 데이터 가공, 최신 인공지능 기술 활용 등 다채로운 전략 수행과 협업을 통해 <2021 인공지능 그랜드 챌린지> 3차 대회에서 1위를 달성하여 <과학기술정보통신부장관상>을 수상하고 2022년 후속 연구를 위한 연구비 지원을 받을 수 있었습니다.
또한, 세밀한 음성 처리에 대한 기술력 검증 및 후속 연구를 통한 버추얼 휴먼 사업의 음성 처리 기술을 고도화할 수 있는 발판을 마련할 수 있어 좋은 경험이었습니다.
