본 글에서는 줌인터넷 부설연구소 팀이 과기정통부 주최 '인공지능 R&D 그랜드 챌린지' 대회를 준비한 과정과 그 결과를 소개하고자 합니다.
줌인터넷 부설연구소 팀은 지난 7월 개최된 과학기술정보통신부 주최 ‘인공지능 R&D 그랜드 챌린지[1]’ 대회에서 상황인지 트랙 2위라는 성과를 거뒀습니다.
인공지능 R&D 그랜드 챌린지 대회는 인공지능을 활용한 '가짜뉴스 찾기', '합성사진 판별' 등 사회문제 해결을 주제로, 지난 2017년부터 매년 개최되고 있습니다.
특히 이번 대회는 최근 전세계적으로 급증하고 있는 지진, 화재 등 대형복합재난으로 인한 피해를 최소화하기 위해 인공지능과 로보틱스를 이용하여 인명을 신속 구조하는 기술 개발을 목표로 진행되었습니다.
대회는 '상황인지(시각지능)', '문자인지(시각지능)', '음향인지(청각지능)', '로보틱스 제어(제어지능)' 등 총 4가지 트랙으로 나뉘어 진행됐습니다. 이 중, 줌인터넷 팀은 드론과 같이 로봇으로 촬영된 동영상 내에서 구조자와 특정 사물의 수를 파악해야 하는 '상황인지' 트랙에 참가했습니다.

1. 문제환경
먼저 주어진 문제를 인공지능으로 해결하기 위해 문제환경을 4가지로 정의해 보았습니다.
- Camera Configuration
객체 검출(Object Detection)이나 객체 추적(Object Tracking)에 있어 동영상이 촬영되는 환경은 매우 중요합니다. 카메라가 고정되어 있는지 혹은 물체의 크기가 일정한지 등의 조건에 따라 접근할 수 있는 알고리즘이 다양하기 때문입니다. 본 대회에서는 비행 중인 드론으로부터 촬영된 영상이 주어졌기 때문에 카메라가 고정되지 않고 수시로 움직여 영상의 각도와 물체와의 거리가 다양하다는 특징이 있었습니다. - Small Objects
상공에서 드론으로 촬영된 영상이기 때문에 영상 속 사람 혹은 사물의 크기가 상대적으로 작게 나타나게 됩니다. 대회에 사용되는 영상 데이터의 해상도는 FHD(1920x1080)로, 기존에 공개되어 있는 ImageNet[2]이나 COCO dataset[3]과는 데이터 유형이 다르기 때문에 ImageNet과 COCO dataset으로 미리 학습된(pre-trained) Object Detection 모델을 단순히 가져다 쓰면 정확도가 낮을 것으로 예상되었습니다. - Multiple Object Tracking
주어진 동영상에서 사람과 지정된 사물의 등장횟수를 계산해야 하기 때문에 다수의 물체를 동시에 찾아내고, 구분할 수 있어야 했습니다. 현재 영상 프레임(Frame)을 기준으로 다음 영상 프레임에서의 물체 위치를 예측하고, 그 결과값에 대한 반복 학습을 통해 문제를 해결해 나가기로 했습니다. - Occlusion
Occlusion은 Object Tracking 분야에서 활발히 진행되는 연구 주제 중 하나로, 동영상 속에서 객체(Object)가 다른 객체 혹은 배경으로부터 일부분 혹은 전체가 가려져서 안보이는 것을 의미합니다. 영상 속 사람이 다른 사람으로 인해 가려졌다가 다음 프레임에서 재등장할 수 있고, 아예 화면 밖으로 사라질 수 있기 때문에 이 인물들이 동일 인물임을 인지하도록 Occlusion을 처리할 필요가 있었습니다.

2. 해결과정
위의 문제 상황을 중점적으로 고려하여 문제를 해결해 나갔습니다. 우선, Object Tracking을 하기 위해서는 카메라를 고정된 환경으로 만들어 주는 것이 중요합니다. 이를 위해 카메라의 움직임을 계산하여 카메라 중심의 전역 좌표계(Global coordinate)를 만들어주는 Camera Homography 모듈을 개발했습니다. 또한, 입력 영상 속 찾고자 하는 물체의 크기가 상대적으로 작게 나타나는 환경에서 강인한 객체 검출을 위한 Object Detection 모듈을 개발했습니다. 마지막으로 이렇게 두 모듈로부터 나온 결과 정보를 통합하여 찾고자 하는 물체를 설계하고, 이를 이용해 Occlusion을 처리하는 Multiple Object Tracking 모듈을 개발했습니다.
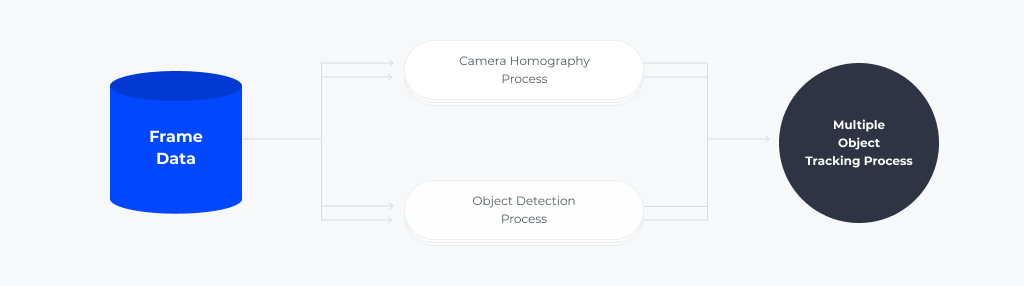
1) Camera Homography
(1) Feature Extraction & Camera Calibration
Homography란 2차원 상에서 물체의 변환 관계를 알 수 있는 변환 행렬을 의미합니다. 예를 들어 2차원 상에 놓여있는 두 사각형이 있을 때, 한 쪽 사각형에서 다른 쪽 사각형으로 모든 점들을 이동시킬 수 있는 변환 행렬을 Homography 행렬이라고 합니다. 이 Homography를 계산하기 위해서는 두 사각형을 구성하는 점들의 대응 관계를 알아야 합니다.
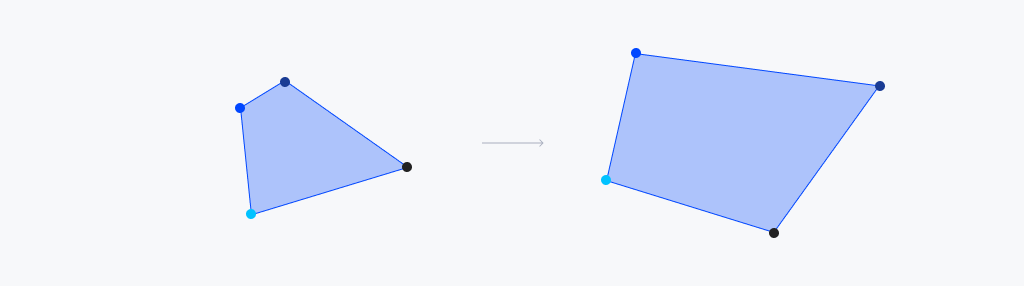
우리가 만일 두 영상 프레임 사이의 대응 관계가 존재하는 점들을 안다면 이를 이용해 Homography 행렬을 계산할 수 있습니다. 여기서 계산된 변환 행렬은 카메라의 움직임 정보를 의미하게 됩니다.
동영상 속 프레임마다 대응점들을 찾기 위해 특징점 추출(Feature Extraction)을 수행했고, 이들을 매칭시켜 Camera Homography를 계산했습니다. 이를 통해 카메라를 특정 시점으로 고정시킨 다음, 영상을 재변환해 카메라 중심의 좌표계를 만들었습니다.

2) Object Detection
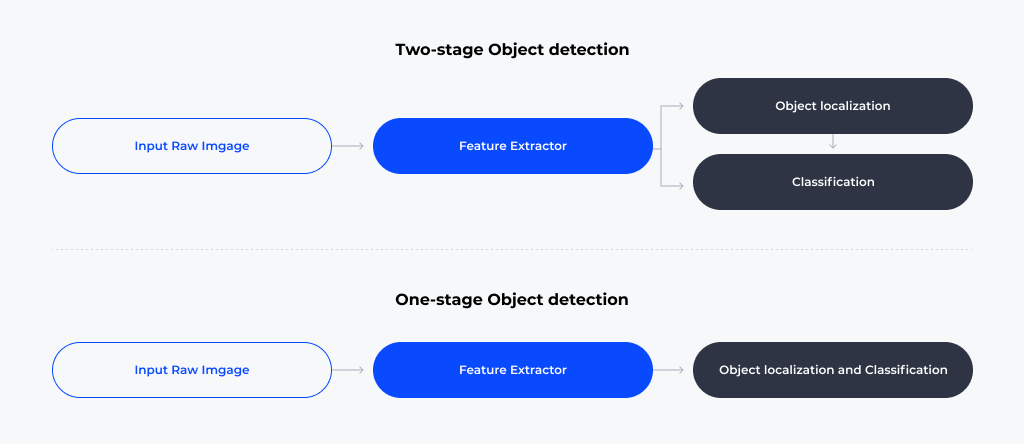
(1) One-Stage Detector using CNN
딥러닝을 이용한 Object Detection 알고리즘은 크게 입력 영상으로부터 객체가 존재하는 위치를 찾아내고, 그 객체가 어떤 종류인지 구별하는 두가지 과정으로 이루어져 있습니다. 두 과정을 병렬적으로 수행하고 나중에 통합하는 검출 알고리즘을 Two-stage Object Detection이라고 하고, 이를 한번에 수행하는 검출 알고리즘을 One-stage Object Detection이라고 합니다.
One-stage Object Detection은 Two-stage Object Detection에 비해 정확도가 느리지만 객체 검출 속도가 빠르기 때문에 실시간에 준하는 Object Detection 성능을 내야하는 문제에 적합합니다. 대회 당일 5시간 동안 500개의 영상을 처리해야하는 그랜드 챌린지 문제 상황을 고려했을 때, One-stage Object Detection을 적용하는 것이 적합하다고 판단했습니다.
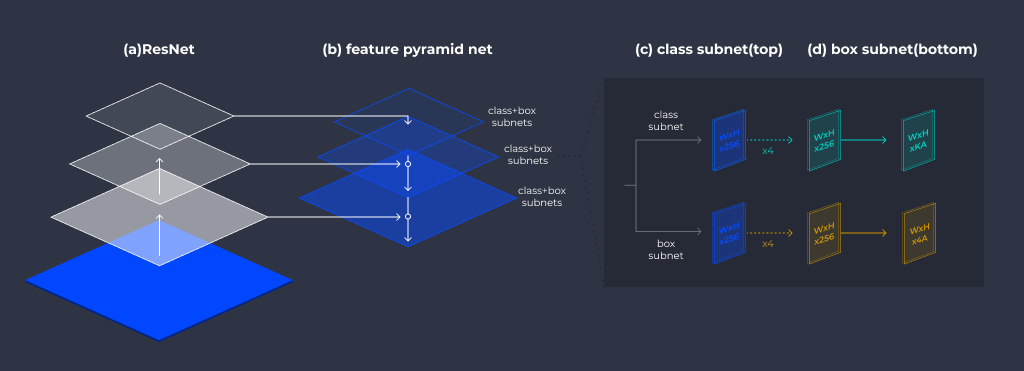
드론 영상의 경우, 카메라가 높은 곳에서 촬영을 하므로 객체가 상대적으로 작게 나타나기 때문에 검출 과정에서 False Positive의 오검출이 많이 발생할 수 있습니다. 이를 해결하기 위해 우리는 RetinaNet[4]을 사용하여 객체 검출을 수행했습니다.
RetinaNet은 입력 영상의 크기를 줄여가며 Feature Extraction을 수행해, 다양한 크기의 객체 정보를 찾아낼 수 있는 Feature Pyramid 방법을 사용하고 있습니다. 또, 배경 부분에서 발생하는 오검출인 False positive를 효과적으로 줄이는 Focal Loss라는 loss function을 고안하여 보다 정확하게 객체를 검출할 수 있습니다.
(2) Split & Merge Detection
대회에 사용되는 영상은 고해상도로, 기존에 공개된 데이터셋과는 유형이 다르기 때문에 단순히 pre-trained Object Detection Model을 쓰면 성능이 상당히 낮게 나타날 것으로 판단했습니다. 그렇다고 해서 고해상도의 공개 데이터셋을 구하거나 직접 제작하기에는 시간과 비용이 상당히 들기 때문에 이러한 문제를 해결할 방법을 찾아야 했습니다.
우리는 주어진 데이터셋을 최대한 활용하기 위해 고해상도의 영상을 분할하여 각각 독립적으로 Object Detection을 수행한 다음, 결과들을 병합했습니다. 영상을 분할할 경우 객체의 상대적인 크기가 전체 영상에 비해 커지기 때문에 일반적인 데이터셋 유형에 가까워지는데요. 따라서 기존에 공개된 pre-trained model을 이용해 대회 문제 상황에 적합한 Object Detector를 구현할 수 있었습니다.
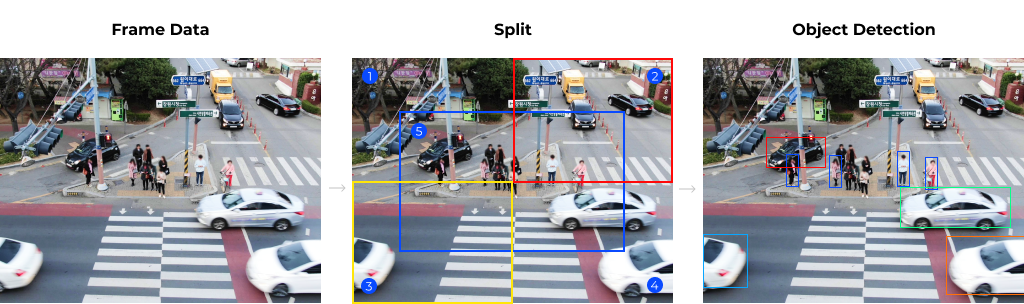
3) Multiple Object Tracking
(1) Modeling - Motion Model
다수의 객체를 정확하게 추적하기 위해서는 일반적으로 객체들을 잘 구분하고, 객체의 일부분 혹은 전부가 가려지거나 화면 밖으로 사라지고 재등장하는 경우들(Occlusion)을 잘 처리해야 합니다. 문제 환경에 따라 고려해야할 점들이 달라지므로, 이에 적합한 객체 모델을 정의하고 설계하는 것이 중요한데요. 이를 위해 우리는 Motion Model과 Visual Model을 설계하고, 둘을 결합한 객체 모델을 제작했습니다.
앞서 Object Detection Process에서 검출한 객체를 Camera Homography Process로부터 나온 전역 좌표계와 통합시켜 영상 속 객체들의 위치 정보를 구할 수 있었는데요. 이 위치 정보를 가지고 선형 운동을 하는 물체의 궤적을 예측하는데 사용되는 Kalman Filter[5] 알고리즘을 이용해 Motion Model을 구성했습니다. Kalman Filter는 이전 시점까지의 객체 위치 정보를 학습해 속도 정보를 모델링하여 현재 시점의 위치를 예측합니다. 현재 시점의 실제 위치 값을 기반으로 기존의 속도 정보를 보정해 다음 시점 예측에 활용하게 됩니다.

(2) Modeling - Visual Model using LSTM
대회의 문제 환경인 드론 영상에서는 카메라가 높은 위치에서 촬영을 하기 때문에 객체들의 움직임이 작게 보여집니다. 이로 인해 정류장이나 신호등 앞에서 기다리는 사람들의 모습을 보면 움직임이 없거나 거의 비슷하게 움직이는 특징을 갖고 있습니다. Motion Model만 사용하게 되면 움직이지 않는 물체나 다수의 물체가 가까이에 있는 환경에서 좋은 성능을 낼 수가 없기 때문에 검출된 객체 정보를 이용해 객체의 모습을 기억하고 서로 구분해낼 수 있는 Visual Model이 필요했습니다.
영상은 2차원으로 정보를 보여주지만, 실제 세계는 3차원 구조이므로 객체가 회전하는 경우 영상으로 보여지는 동일한 객체의 모습이 달라지게 됩니다. 영상 속에서 객체의 모습은 일정하지 않고 바뀔 수 있으므로, 객체의 모습을 하나만 보는 것이 아니라 이전 프레임에 나타났던 모습들을 종합적으로 고려하여 객체를 정확하게 인식해야 합니다. 우리는 객체의 다양한 모습을 학습하기 위해 이전 프레임의 정보를 활용하는 LSTM[6] 구조를 이용하여 Object Detection Process에서 검출한 객체 정보를 학습하는 Visual Model을 구성했습니다.
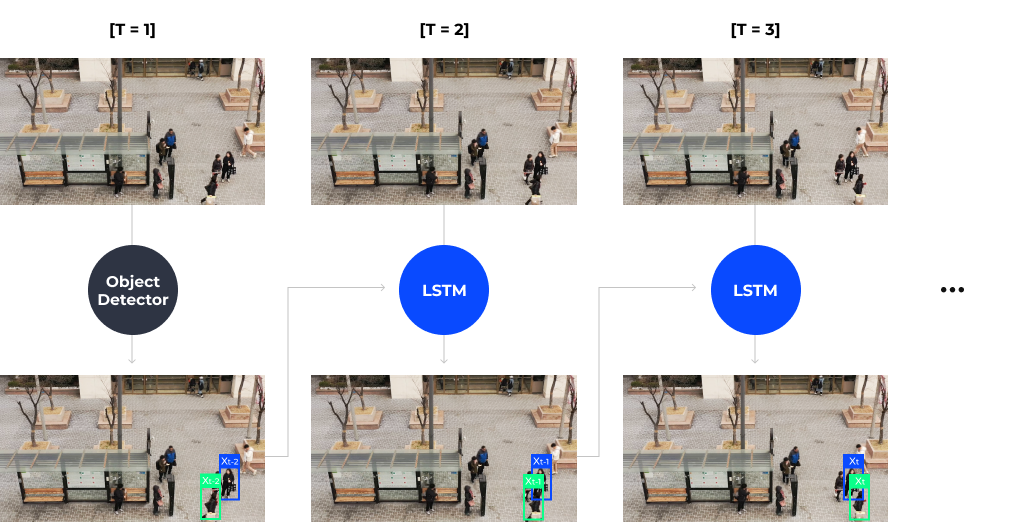
최종적으로 Motion Model, Visual Model 이 두가지 모델을 결합해 Multiple Object Tracking을 수행했습니다. 이전 영상 프레임의 정보를 기반으로 객체 모델을 학습하고, 현재 프레임에서 다수의 객체 위치를 예측한 다음, 실제 위치정보와의 차이를 계산하여 객체 모델을 보정 및 학습하고 다시 그 다음 프레임을 예측하는 과정을 진행했습니다.
3. 마치며
실제 대회에서 우리는 5시간 안에 FHD 해상도 10fps의 30초 길이 영상 500개를 처리하여 영상별로 사람과 지정된 객체들(자동차, 자전거, 오토바이, 소화기, 소화전)의 출현 횟수를 계산해야 했습니다. 영상의 모든 프레임을 다 처리한다는 가정 하에 1초에 최소 9개의 프레임을 처리할 수 있는 알고리즘을 고안해야 했고, 이는 거의 실시간에 준하는 성능이어야 했습니다. 이를 위해 우리는 추가적으로 멀티 프로세싱 기법을 적용시켜 최대한 병렬처리가 가능하도록 구현했습니다.
카메라가 움직이고 심지어 객체가 상대적으로 작게 보여지는 드론 환경에서 객체들을 식별하는 것은 상당히 까다로운 문제였습니다. 거기에 여러 객체를 동시에 tracking하고, occlusion까지 처리해야 하는 높은 난이도의 대회였던 것 같습니다. 준비 기간이 길지 않았지만, 다행히 좋은 성적을 거두게 되었고 해당 주제로 후속 과제를 진행하게 되었습니다.
향후 연구 방향으로는 대회 취지에 맞춰 실제 인명구조용 드론에 해당 알고리즘이 탑재되어 실시간으로 구조자를 파악할 수 있도록 알고리즘을 경량화시킬 예정입니다. 더 나아가 문제 환경에 맞는 데이터셋을 제작하여 더 강인한 모델이 되도록 학습시킨다면 정확도와 속도 둘 다 향상시킬 수 있을 것입니다.
끝으로 이번 대회와 같이 인공지능 기술을 사회적 가치를 지향하고 공익을 추구하는 방향으로 발전시킬 수 있는 대회가 많이 나오기를 바라며, 이에 대한 지속적인 지원을 통해 더 많은 개발자들이 다양한 사회문제에 관심을 가지고 함께 기술을 발전시켜 나가기를 희망합니다.



참고문헌
[1] https://www.ai-challenge.kr
[2] Deng, Jia, et al. “Imagenet: A large-scale
hierarchical image database.” 2009
IEEE conference on computer vision and pattern recognition. Ieee,
2009.
[3] Lin, Tsung-Yi, et al. “Microsoft coco:
Common objects in context.” European
conference on computer vision. Springer, Cham, 2014.
[4] Lin, Tsung-Yi, et al. “Focal loss for
dense object detection.” Proceedings
of the IEEE international conference on computer vision. 2017.
[5] Kalman, Rudolph
Emil. “A new approach to linear filtering and prediction problems.” Journal of basic Engineering 82.1
(1960): 35-45.
[6] Hochreiter, Sepp,
and Jürgen Schmidhuber. “Long short-term memory.” Neural computation 9.8 (1997): 1735-1780.