딥러닝(Deep Learning)은 뛰어난 성능과 높은 모델의 확장성(Scalability)으로 인해 많은 주목을 받았고, 요즘 산업계에서도 활발하게 적용되고 있습니다. 하지만 모델의 높은 확장성은 또 다른 문제를 불러오게 되었습니다.
기본적으로 딥러닝 모델의 성능은 그 크기에 비례하는 경향을 보입니다. 그렇다면 우리가 좋은 성능의 모델을 얻기 위해서는 계속해서 모델을 키우기만 하면 될까요? 딥러닝 모델이 커지면 어떤 문제점들이 있을까요? 작은 딥러닝 모델로도 큰 모델과 같은 성능을 얻을 수 있을까요?
이 글에서는 이러한 의문점을 연구하는 분야인 모델 압축(Model Compression)에 대해 이야기 해보려고 합니다. 특히, 현재 자연어처리(Natural Language Processing, NLP) 분야에서의 모델 발전 방향과 문제점, 모델 압축 방법론의 등장, 관련된 논문들을 다루려고 합니다.
Big Learning: Larger Dataset, Larger Model, Pre-training, Fine-tuning
딥러닝은 CNN(Convolutional Neural Network)이 2012년 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 뛰어난 성능으로 우승을 하며, 큰 주목을 받았습니다. 그 이후로 컴퓨터 비전 분야에서는 VGGNet(2014), GoogLeNet(2015), ResNet(2015), DenseNet(2016) 등의 다양한 네트워크 아키텍처가 등장하여 모델을 점점 깊고 크게 만들어 나갔고, 이러한 거대한 모델을 거대한 이미지 데이터셋을 이용하여 미리 학습(Pre-train)시키고, 이를 특정 응용 분야에 맞춰 새로 학습(Fine-tune)하는 방식의 접근법이 주류가 되었습니다.
반면, 자연어 처리(NLP) 분야의 초기 딥러닝 연구 방향은 비전 분야와는 약간 달랐습니다. 자연어 처리에서는 'RNN(Recurrent Neural Network)'이라고 하는 연속된 데이터를 다루는데 특화된 모델을 주로 사용하였습니다. RNN은 모델이 처리해야 하는 데이터가 길어짐에 따라 기울기(Gradient)가 사라진다는 문제 [1]와 다음 입력 데이터 처리를 위해 이전 데이터가 필요하여 병렬화가 어렵다는 문제가 있었습니다. RNN 모델이 가진 한계로 인해, 자연어 처리에서는 컴퓨터 비전에서만큼 모델을 거대화하기 어려웠습니다.
또한, 컴퓨터 비전에서는 ImageNet에서 분류 학습을 한 모델이 다른 분야에서도 필요한 특징을 잘 뽑아내었는데요. 자연어 처리에서는 이에 대응되는 거대한 데이터셋과 다른 분야에서 특징을 잘 뽑아내기 위한 사전 학습 방법이 잘 알려져 있지 않아, 이미 학습된 모델이 다른 분야에 활용되기 어려웠습니다. 자연어 처리 분야에서 사전 학습을 위한 주된 접근법은 거대한 말뭉치(Corpus)에서 단어 임베딩(Word embedding) [2]을 학습하여 재사용하는 정도였죠.
하지만 2018년에 Google이 BERT(Bidirectional Encoder Representations from Transformers) [3]를 발표하며, 자연어 처리 분야에서도 거대한 모델들이 속속 등장하기 시작하였습니다. BERT는 Transformer [4] 기반의 모델로, 자연어 처리에서도 컴퓨터 비전과 마찬가지로 거대한 모델의 사전 학습 - 재학습이 가능해졌고, 다양한 문제들에서 뛰어난 성능을 보여주었습니다.
이후 다양한 형태의 바리에이션이 나오면서 BERT는 현재 NLP 연구의 주류가 되었습니다. 현재 NLP 연구는 거대한 모델을 만들고, 많은 데이터를 이용해 모델을 미리 학습한 후 응용 분야에 맞춰 재학습하는 접근 방식을 취하고 있습니다.
▶ 'BERT를 활용한 챗봇 시스템' 소개글 : https://blog.est.ai/2019/11/task-oriented-dialog-systems-meet-bert/
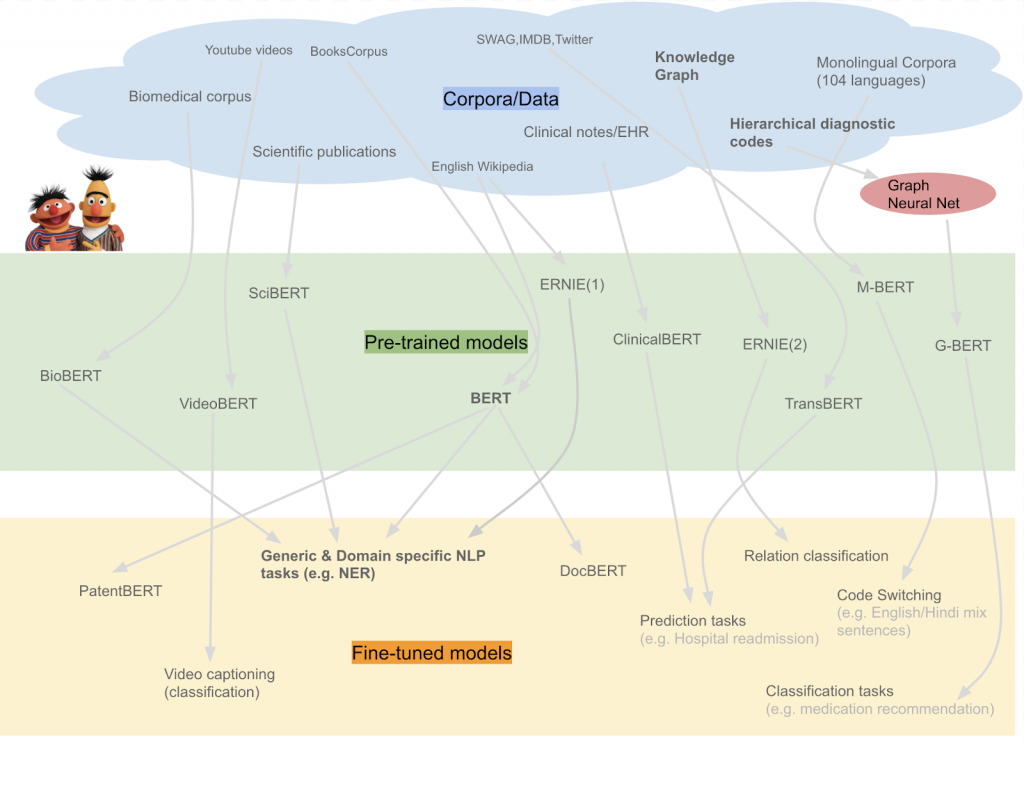
모델 압축의 필요성
딥러닝을 이용해 해결하려는 문제가 복잡해지면서 요구되는 모델의 크기가 급격하게 증가하게 되었고, 이에 따라 다양한 문제점들이 등장하기 시작했습니다.
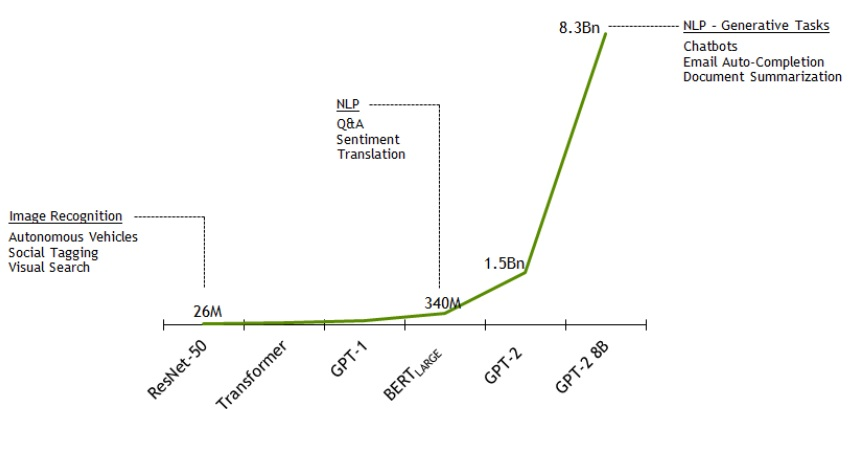
딥러닝 모델 크기가 증가함에 따라 발생 가능한 문제들
- Memory Limitation : 모델이 커지면서 가장 먼저 문제가 될 수 있는 것은 메모리 사이즈입니다. BERT 파생 모델들의 사이즈가 점점 커지면서 하나의 GPU에서 큰 모델을 학습하는 것이 점점 어려워지고 있습니다 [7]. 또한 자연어 처리 분야에서 큰 배치 사이즈가 학습에 효과적이라는 의견이 나오면서 [8] 사전 학습에 사용되는 배치 크기가 점점 커지는 추세를 보이고 있고[9,10], 이러한 배치 사이즈의 증가는 메모리에 많은 부담이 되고 있습니다.
- Training/Inference Speed : 학습에 필요한 gradient는 모델의 크기에 비례하기 때문에 분산 학습을 통해 학습 속도를 올리더라도, 모델이 커짐에 따라 학습에 보다 많은 시간이 소요되게 됩니다. 학습은 한 번만 진행되므로 시간이 오래 걸려도 괜찮을 수 있지만, 모델 크기가 증가하면서 추론에 걸리는 시간 역시 늘어나기 때문에 문제가 될 수 있습니다.
- Worse Performance : 이런 문제점을 해결하기 위한 한 가지 접근 방법 중 하나는 분산 학습입니다. 기존의 많은 연구들은 1)데이터 병렬화와 2)모델 병렬화 방식과 같이 복수의 GPU를 사용한 학습을 통해 이 문제를 해결하려 하였습니다 하지만 분산 학습으로 모델을 학습하더라도 여전히 문제는 남습니다. 같은 데이터에서 단순히 모델만을 키운다고 성능이 계속해서 증가하지는 않기 때문입니다. [11]. 지나치게 큰 모델은 과적합(overfitting)하기 쉽고 [12], 이를 막기 위해서는 더 많은 데이터를 사용하거나, 정규화(regularization) 방법을 도입하여 해결할 필요가 있습니다 [13].
- Practical problems : 분산 학습을 한다고 하더라도 모델이 커짐에 따라, 많은 GPU를 준비해야 하는 것은 작은 회사/연구소/대학원 등에서는 부담이 될 수 있습니다. 또한, 모바일/자동차 같은 환경에서는 휴대성, 전력 소모 등의 이유로 GPU 사용에 제한을 많이 받을 수 있어, 이와 같은 실용적인 측면에서의 문제도 고려해야 할 필요가 있습니다.

이런 상황에서 현재 주목을 받고 있는 연구 분야가 모델 압축(model compression)입니다. 모델 압축은 다양한 방법을 이용하여 딥러닝 모델의 성능을 유지하면서 크기를 줄이는 것을 목표로 하고 있습니다. 이를 위해 주로 사용되는 방법은 다음과 같은 것들이 있습니다.
모델 압축을 위한 기본적인 접근 방법들
Gordon은 모델 압축을 위한 기본적인 접근 방법들을 다음과 같은 여섯가지 방법으로 정리하였습니다 [16].
- 가지치기 (Pruning) : 학습 후에 불필요한 부분을 제거하는 방식으로, 가중치의 크기에 기반한 제거, 어텐션 헤드 제거, 레이어 제거 등 여러가지 방법을 사용합니다. 몇몇 방법은 prunability를 제거하기 위해 학습 중에 정규화 방법을 도입하기도 합니다 (layer dropout).
- 가중치 분해 (Weight Factorization) : 가중치 행렬을 분해하여 두 개의 작은 행렬의 곱으로 근사하는 방법입니다. 이 방법은 행렬이 낮은 랭크를 가지도록 하는 제약조건(low-rank constraint)을 도입합니다. 가중치 분해는 토큰 임베딩이나 feed-forward / self-attention layer의 파라미터에 적용할 수 있습니다.
- 지식 증류 (Knowledge Distillation) : 미리 잘 학습된 큰 네트워크(Teacher network)로부터 실제로 사용하고자 하는 작은 네트워크(Student network)를 학습시키는 방식입니다. 훨씬 작은 Transformer 모델을 pre-training / downstream-data에 대해 기본부터 학습시킵니다. 원래대로라면 학습이 잘 안 되지만, fully-sized model의 값을 soft label로 사용하면 최적화가 더 잘 이루어집니다. 몇몇 방법들은 추론 시간을 빠르게 하기 위해 BERT를 다른 형태의 모델(LSTM, etc.)로 증류하기도 합니다. 이외 다른 방법들은 teacher에 대해 더 자세히 분석하여 출력값 뿐만 아니라, 가중치 행렬이나 hidden activation 값들을 사용하기도 합니다.
- 가중치 공유 (Weight Sharing) : 모델의 일부 가중치들을 다른 파라미터들과 공유하는 방식입니다. 예를 들어 ALBERT는 BERT의 self-attention layer와 같은 가중치 행렬들을 사용하고 있습니다. (ALBERT는 구글이 작년 9월 발표한 BERT의 새로운 버전으로, BERT보다 가볍고 처리 속도가 높아진 점이 특징입니다.)
- 양자화 (Quantization) : 부동 소수점 값을 잘라내서 더 적은 비트만을 사용하는 방식입니다. 양자화된 값은 학습 과정 중에 배울 수도 있고, 학습 후에 양자화될 수도 있습니다.
- Pre-train vs. Downstream : 일부 방법들은 BERT를 특정 downstream task에만 맞게 압축하지만, BERT를 task와 무관하게 압축하는 방법들도 있습니다.
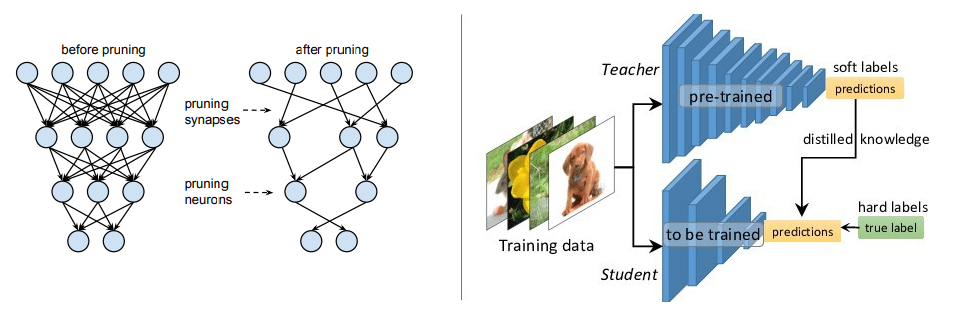
관련 논문들 [16]
다음 논문 정리와 실험들은 Gordon이 블로그에 정리한 내용을 옮긴 것입니다.
다음 표는 BERT를 압축하기 위한 다양한 논문들을 위 방법론에 따라 정리한 것입니다. 실용적인 측면에서 성능이 괜찮은 것들을 찾는다면 ALBERT, DistilBERT, MobileBERT, Q-BERT, LayerDrop, RPP를 보는 것을 추천합니다. 여러 압축 방법들을 같이 적용할 수도 있지만, pruning 논문 중의 일부는 실용적인 측면보다 이론적인 내용을 다루기 때문에 먼저 확인해 보시는 것을 권장합니다.
논문 결과 비교 [16]
앞서 소개한 논문에서 보고한 내용들을 파라미터 감소, 추론 속도 증가, 정확도 측면에서 아래 표와 같이 정리해 보았습니다.
Highlights
다음 논문들은 모델 압축에 관해 눈여겨 볼 만한 논문이라 생각되어 별도로 소개합니다. 1)ALBERT 논문은 위에서 언급한 방법들을 이용하여 큰 모델 압축률을 보여주었다는 측면에서 선택하였고, 2)The Lottery Ticket Hypothesis 논문은 연구 측면에서 기존 pruning 방식에 대한 문제 제기와 이를 기반으로 한 새로운 연구 방향의 제시에 의의가 있다고 생각하여 선택하였습니다.
1) ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
(Google, 2019, ICLR 2020 Spotlight)
ALBERT는 Google에서 2019년에 발표한 논문으로, 기존 BERT의 압축을 위한 두 가지 parameter-reduction 방법과 pre-train 단계의 새로운 loss를 도입하였습니다.
ALBERT의 기본적인 아이디어는 'BERT의 파워는 컨텍스트를 고려한 hidden-layer embedding에서 나온다'는 것입니다. 따라서 ALBERT에서는 컨텍스트의 영향을 받지 않는(context-independent) WordPiece embedding의 크기를 줄이고, 이렇게 줄어든 크기로 hidden layer를 늘리는 방법을 사용하였습니다.
ALBERT에서 모델 압축을 위해 사용한 첫 번째 방법은 factorized embedding parameterization입니다. 기존 BERT는 각 WordPiece 별로 embedding을 만들어서 $ O(V times H) $ 크기의 embedding parameter를 가졌는데, 이를 두 개의 행렬로 나누어 $ O(V times E + E times H) $로 만들었습니다. 이를 통해 WordPiece embedding과 hidden layer size의 크기를 분리하고, hidden layer를 크게 만들 수 있었습니다.
그리고 다음 방법은 cross-layer parameter sharing입니다. ALBERT에서는 전체 layer들이 모든 (FFN, Attention) 파라미터를 공유합니다. Hidden layer들의 파라미터가 공유되기 때문에 layer의 크기가 커지는 것의 부담을 줄이고, 네트워크 파라미터를 안정화시킬 수 있습니다.
이러한 방법을 통해 ALBERT는 기존 BERT-large와 비슷한 설정에서 5% 정도의 파라미터를 가지고 1.7x 빠른 트레이닝이 가능하게 만들었습니다.
2) The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
(Frankle, J., & Carbin, M. 2018, ICLR 2019 Best Paper)
THE LOTTERY TICKET HYPOTHESIS는 2019년에 ICLR에 발표된 논문으로, lottery ticket 가설을 기반으로 효과적인 weight pruning 알고리즘을 제안하고 있습니다. lottery ticket 가설은 '가지치기를 통해 만들어진 모델은 처음부터 학습하기 어렵고, 원래 모델보다 낮은 정확도를 보인다'는 기존 실험들을 기반으로 제안되었는데요. 이 내용은 '랜덤하게 초기화 된 fully-connected와 convolution으로 구성된 네트워크를 같은 파라미터로 초기화하면 기존 모델보다 더 빨리 학습하고, 비슷하거나 보다 높은 정확도에서 훨씬 적은 파라미터로 구성된 모델이 존재'하게 된다는 것입니다.
이러한 가설에 기반해, 저자들은 다음과 같은 알고리즘을 제안하였습니다.

저자들은 논문에서 Lenet, VGG variants, Resnet-18을 대상으로 제안된 알고리즘을 이용하여 파라미터를 원래 모델의 10~20% 정도 (또는 그 이하)로 줄였습니다. 이 결과는 위에서 언급한 ALBERT와 같은 뛰어난 가중치 pruning 방법들에 비하면 실용적인 측면에서 다소 아쉬움이 있을 수 있습니다. 하지만 이 논문에서 제안한 방법이 '일반적인 네트워크에 적용 가능한 방법'이라는 점과, 기존에 모델 압축에 제기된 의문인 ‘왜 처음부터 작은 모델을 만들어서 학습하지 않고 큰 모델을 만들어서 압축을 해야 하는가’에 대한 가설을 제시하고 있다는 점에서 읽어봐야 할 논문이라고 생각합니다.
Conclusion
지금까지 NLP 분야에서의 딥러닝 모델 발전 방향과 모델 압축 방법의 필요성, 방법론, 관련 논문들을 소개하고 내용을 살펴보았습니다.
딥러닝이 기존 머신러닝 방법론들과 비교해서 현재 산업계에서 많이 활용되고 있는데는 여러 이유가 있겠지만, 가장 큰 요인은 보다 쉽게 모델을 스케일업하고, 많은 데이터를 사용하여 성능을 향상시킬 수 있다는 점일 것입니다. 하지만, 모델의 크기가 커지는 것에 따른 다양한 비용들이 있는 만큼 이제는 모델을 키우는 것이 아니라 잘 줄이는 방법에 대한 고민이 필요한 시점이 아닐까요? 앞으로 딥러닝 모델압축과 경량화에 대한 필요성이 더욱 대두되고, 그에 대한 다양한 연구도 많이 이어질 것으로 기대됩니다.
참고문헌
[1] Pascanu, Razvan, Tomas Mikolov, and Yoshua Bengio. “On the difficulty of training recurrent neural networks.” International conference on machine learning. 2013.
[2] Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.
[3] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[4] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems. 2017.
[5] Rajasekharan, Ajit. “A review of BERT based models” 18 Jan. 2019, towardsdatascience.com/a-review-of-bert-based-models-4ffdc0f15d58
[6] Narasimhan, Shar. “NVIDIA Clocks World’s Fastest BERT Training Time and Largest Transformer Based Model, Paving Path For Advanced Conversational AI” NVIDIA Developer Blog, 13 Aug. 2019, devblogs.nvidia.com/training-bert-with-gpus/.
[7] https://github.com/google-research/bert/
[8] Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
[9] Yang, Zhilin, et al. “Xlnet: Generalized autoregressive pretraining for language understanding.” Advances in neural information processing systems. 2019.
[10] Clark, Kevin, et al. “ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators.” International Conference on Learning Representations. 2019.
[11] Lan, Zhenzhong, et al. “Albert: A lite bert for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942 (2019).
[12] Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
[13] Ng, Andrew. “Nuts and bolts of building AI applications using Deep Learning.” NIPS Keynote Talk (2016).
[14] Dean, Jeffrey, et al. “Large scale distributed deep networks.” Advances in neural information processing systems. 2012.
[15] https://github.com/NVIDIA/Megatron-LM
[16] Gordon, Mitchell. “All The Ways You Can Compress BERT” 18 Nov. 2019, mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html
[17] Han, Song, et al. “Learning both weights and connections for efficient neural network.” Advances in neural information processing systems. 2015.
[18] Ganesh, Prakhar. “Knowledge Distillation : Simplified” 13 Aug. 2019, towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764