일상 생활에서 우리는 영수증, 증명서, 계약서 등 다양한 문서를 접하는데요. 이렇게 다양한 문서 속에서 필요한 정보를 추출하고 처리하기 위해서는 많은 노력과 시간이 소요됩니다. 최근 이러한 불편을 해결할 수 있는 ‘자동화’에 대한 관심이 증가하면서 ‘Document Understanding(문서 이해)’의 중요성이 커지고 있는데요. 이번 글에서는 여러 논문들을 바탕으로 문서 이해 인공지능(AI)의 최신 연구 동향을 살펴보고자 합니다.
1. Document Understanding 이란?
Document Understanding은 ‘문서 이해’ 또는 ‘문서 인식’이라고도 하는데요. 문서에서 필요한 데이터를 추출하여 유의미한 정보를 도출해내는 것을 말합니다. 이 때, 문서는 대용량일 수도, 텍스트, 이미지 등이 혼합된 비구조화된 문서일 수도 있는데요. 본 글에서는 일상 생활에서 많이 접하는 ‘영수증’과 이와 유사한 ‘인보이스(invoice, 송장)’ 문서를 다룬 연구들을 살펴보려고 합니다.
이 문서들은 여러 산업에서 다수의 사람들이 활용하는 문서로, 거래 시간 및 품목, 수량 등 유의미한 여러 정보들을 담고 있어 현재 문서 이해 AI 연구가 활발히 진행 중인 분야 중 하나인데요. 여기서 문서 이해 AI를 활용하기 위해서는 기본적으로 문장들에 대한 이해가 전제되어야 합니다. 이를 위해 NLP(Natural Language Processing) 과정이 필요하지만, NLP는 보통 1차원으로 된 문장에 잘 작동하도록 발전되어 왔기 때문에 영수증과 같은 2차원 문서에서는 문서 내 위치 및 시각(vision) 정보도 함께 고려되어야 합니다.
흔히 NLP라 하면 가장 먼저 떠올릴 수 있는 ‘챗봇’의 경우, 문장이 첫 글자부터 마지막 글자까지 차례로 들어오기 때문에 1차원이라고 볼 수 있습니다. 하지만, 영수증의 경우 보통 상단에 매장 정보가 위치하고, 중앙에는 상품명과 그 수량, 가격이, 하단에는 총액이나 결제 수단 등의 정보가 각기 다른 폰트와 크기로 담겨 있기 때문에 2차원으로 볼 수 있습니다. 이로 인해 각 글자가 의미하는 내용을 모르더라도, 상대적인 위치와 폰트 크기 정보 등을 바탕으로 그 뜻을 쉽게 유추할 수 있다는 특징이 있죠.

2. 관련 논문 소개
NLP와 vision을 동시에 활용해 문서 이해 작업을 진행하기 위해서는 ‘벡터’의 역할이 중요합니다. 문서를 간단하게 이미지로 표현할 때, 문서의 각 텍스트를 벡터로 표현해 NLP 정보를 넣어야 하기 때문인데요.
만약 ‘나무’, ‘나뭇잎’, ‘동물’이라는 3가지 단어가 주어지고 비슷한 단어끼리 묶어야 한다면, 우리는 자연스럽게 ‘나무’와 ‘나뭇잎’ 간의 연관된 정도가 ‘나무’와 ‘동물’ 보다 더 크다는 것을 압니다. 하지만, 컴퓨터는 이러한 사실을 모르기 때문에 ‘벡터’를 사용해 그 차이를 인지시켜야 합니다. 이를 위해 ‘나무’를 [34, 25, 60, 235]라는 벡터로, ‘나뭇잎’은 [33, 24, 60, 235]로, ‘동물’은 [1, 938, 43, 80]로 가정해보면, ‘나무’에 해당되는 벡터와 ‘나뭇잎’에 해당되는 벡터 사이의 거리(|[34, 25, 60, 235] - [33, 24, 60, 235]|)가 ‘나무’에 해당되는 벡터와 ‘동물’에 해당되는 벡터 사이의 거리(|[34, 25, 60, 235] - [1, 938, 43, 80]|)보다 가깝다는 것을 알 수 있게 됩니다.
지금부터 각 논문에서 어떤 벡터를 사용하여 어떠한 결과를 도출했는지에 초점을 맞춰, 4가지의 논문을 살펴 보겠습니다.
1) Chargrid: Towards Understanding 2D Documents[1]
이 논문은 각 알파벳을 벡터로 사용하여 문서를 grid로 표현했는데요. 예를 들면 [ ab ]라는 문서가 있다면, 앞과 뒤의 빈칸은 [0, 0, …, 0], a는 [1, 0, …, 0], b는 [0, 1, …, 0]으로 나타내어 결과적으로 [ [0, 0, …, 0], [1, 0, …, 0], [0, 1, …, 0], [0, 0, …, 0] ]이라는 grid로 나타내었습니다. 이를 ‘Chargrid’라 하는데요. 학습을 진행할 때 Chargrid를 사용해, 각 알파벳의 원 위치에 그 알파벳에 대한 벡터를 놓아 grid를 만듦으로써 텍스트 뿐만 아니라 위치 정보까지 활용하였습니다.

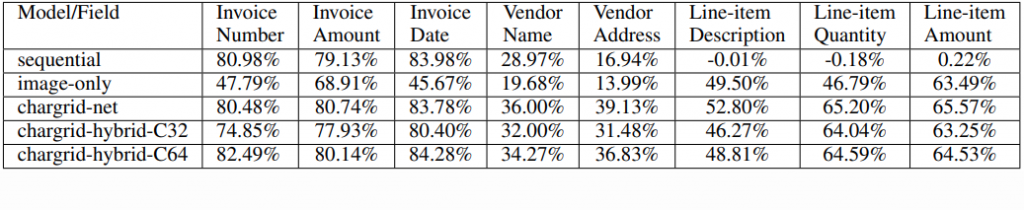
Chargrid는 Invoice 데이터를 이용해서 그 성능을 확인했는데요. 그림2를 보면 해당 문서에서 원하는 정보를 얼마나 정확히 뽑았는지에 대한 값을 수치로 보여줍니다. 숫자로 나타나는 Invoice Number나 Invoice Amount, Invoice Date에서는 80%가 넘는 좋은 성능을 보이지만, 그 외에 주로 문자로 나타나는 Vendor Name이나 Vendor Address의 성능은 그 절반인 40%도 채 되지 않습니다. 이를 통해 알파벳을 벡터로 치환하는 방법으로는 단어의 뜻을 명확히 파악하기 힘들다는 점을 파악할 수 있었습니다.
2) BERTgrid: Contextualized Embedding for 2D Document Representation and Understanding[2]
앞선 Chargrid는 알파벳을 벡터로 대치 사용하기 때문에 동형이의어를 구분하지 못한다는 꽤 치명적인 문제가 있는데요. 예를 들면 ‘TEAR’라는 단어가 상황에 따라 ‘눈물’로, 아니면 ‘찢다’라는 의미로 쓰일 수 있지만, Chargrid에서는 스펠링이 ‘TEAR’로 같기 때문에 그 의미를 반영하지 못한 채 같은 벡터로 표현됩니다. 그렇게 되면 네트워크는 그 차이점을 인지하지 못하고 같은 뜻으로 파악하게 되는데요.
이러한 문제점을 해결하기 위해 ‘BERTgrid’가 등장했습니다. BERTgrid는 문장을 표현할 때, BERT의 출력 벡터를 사용하여 각 단어가 가지는 의미를 벡터로 나타내는데요. 예를 들어 ‘teacher’라는 단어가 있을 때, ‘가르지다’라는 의미의 ‘teach’라는 단어를 하나의 벡터로 나타내고, ‘사람’이라는 의미의 ‘-er’를 또 다른 벡터로 나타내는 것입니다.

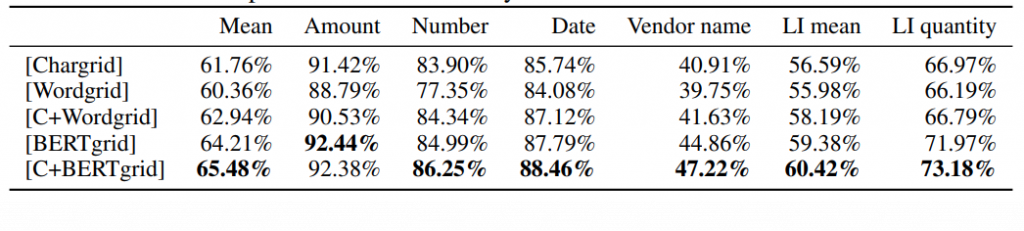
그림4를 보면, 기존 Chargrid 보다 BERTgrid의 성능이 더 뛰어난 것을 볼 수 있습니다. 알파벳 자체를 벡터로 치환하지 않고 BERT를 이용해 의미를 가지는 단어를 벡터로 치환하여 그 성능은 높였지만, 여전히 문자에 비해 숫자로 나타나는 정보들의 정확도가 훨씬 높았습니다. 아무래도 BERT가 문장을 목표로 만들어진 네트워크이다 보니, 문장으로 나타나지 않는 invoice 또는 영수증 처리에서는 그 성능을 최대로 발휘하기 어려웠던 것으로 보입니다.
3) CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor[3]
앞선 Chargrid와 BERTgrid 모두 문서 이미지를 그대로 사용하며, 그 안에 있는 문장만 다른 방식으로 표현해 만든 grid를 입력(input)으로 사용했는데요. 이 방식은 여백이 많은 문서의 특성 상 불필요한 메모리가 많이 소모된다는 문제점이 있습니다.
바로 이 점을 개선한 ‘CUTIE(Convolutional Universal Text Information Extractor)’가 등장했는데요. CUTIE는 BERTgrid와 같이 BERT를 사용해 각 단어를 벡터로 치환했지만, 문서의 전체적인 크기를 줄여 gird를 만들었다는 점에서 차이가 있습니다. 여기서 서로 다른 문단이라는 것을 구별할 수 있도록 여백을 최소했는데요. 실제로 그림5에서 하단의 두 줄을 보면, 맨 아랫줄의 ‘DESTINO:’ 와 그 위의 ‘ORIGEN:’ 사이의 여백이 삭제된 것을 확인할 수 있습니다.

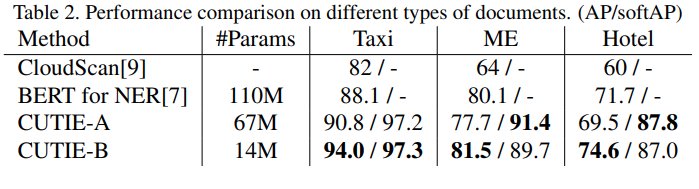
CUTIE는 영수증을 이용해서 그 성능을 확인했습니다. 이번 연구는 영수증을 활용했기 때문에 인보이스로 성능을 확인한 앞선 연구 결과와 객관적인 비교를 하기는 어렵습니다. 그럼에도 불구하고 성능 자체를 비교해보면, 그림6이 그림 2, 4와 비교해 대체적으로 좋은 결과를 얻은 것을 볼 수 있습니다. 이는 영수증이 인보이스에 비해 텍스트의 양이 적은, 비교적 간단한 문서이기 때문인 것으로 보이는데요. 다시 말해, 전체적으로 텍스트에 대한 정확도가 떨어지는 상황에서 문서 내 텍스트가 상대적으로 적게 존재한다면 그에 대한 정확도가 높아진다고 볼 수 있습니다.
4) LayoutLM: Pre-training of Text and Layout for Document Image Understanding[4]
앞서 언급한 Chargrid, BERTgrid나 CUTIEgrid와 같이 grid를 만드는 방식은 텍스트의 위치정보는 잘 반영하지만, 그 외의 vision 정보는 사용할 수 없다는 단점이 있습니다. 다시 말해 텍스트의 위치정보만 활용할 뿐, vision 정보에 해당하는 텍스트 크기나 서체 등의 정보는 사용할 수 없는 건데요. 실생활에서 우리는 제목과 본문을 구분하거나, 내용의 중요도를 나타내기 위해 텍스트 크기, 서체 등을 다르게 사용하기 때문에 사실상 이러한 vision 부분은 상당히 중요한 정보를 많이 담고 있다고 볼 수 있습니다.
바로 이와 같은 vision 정보를 사용하기 위해 등장한 layoutLM은 단어와 그에 해당되는 그림의 일부를 동시에 학습에 사용하는 방식을 사용하는데요. 예를 들면 영수증에 볼드체와 이태릭체로 된 ‘Date’라는 단어가 있을 때 단어를 입력으로 넣을 때는 ‘date’라 넣고, 그에 해당하는 그림은 ‘Date’ 부분을 잘라내어 넣는 것입니다. 물론 이와 동시에 그 단어의 위치정보도 이용해야 하기 때문에 각 네 모서리의 x,y 좌표(layout)를 입력으로 했는데요. 이렇게 하면 텍스트의 위치 정보도 사용함과 동시에 vision 정보도 동시에 활용할 수 있게 되죠.
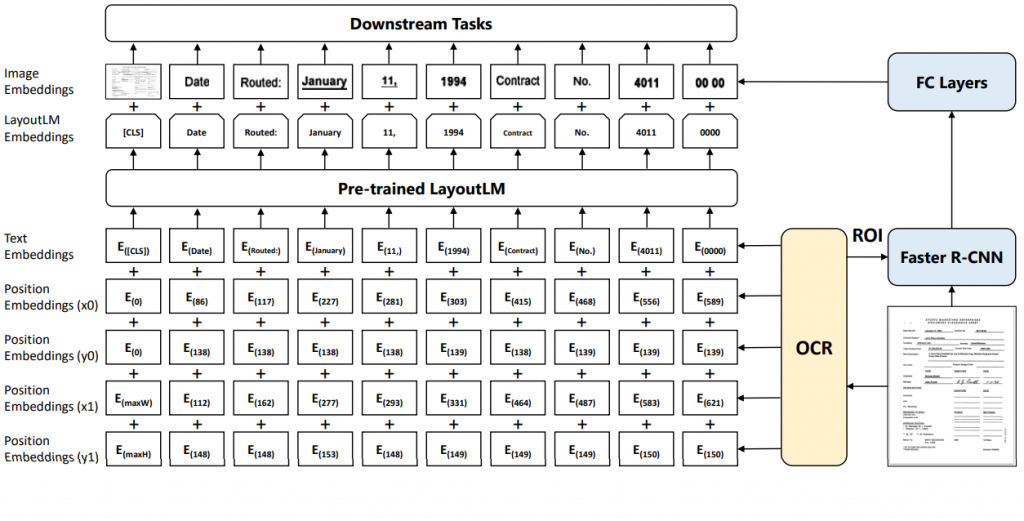
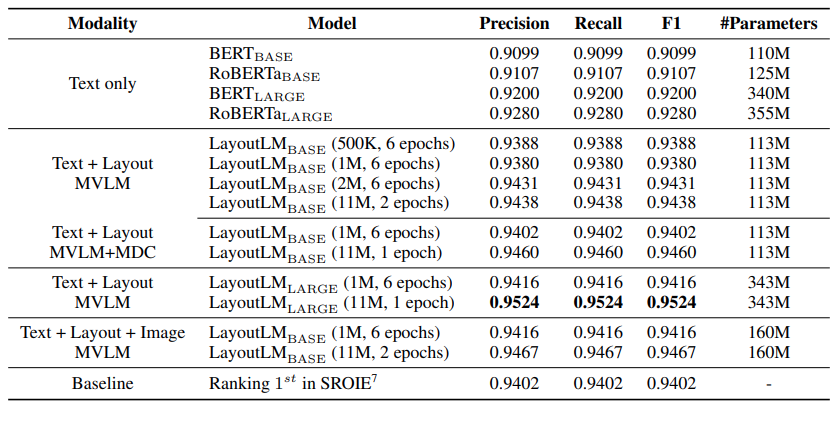
그림8은 invoice를 이용해 LayoutLM의 성능을 측정했습니다. 그림 8을 보면 앞선 3개의 연구들과는 다르게 전체적으로 성능이 매우 좋아진 것을 확인할 수 있습니다. 또한 문자에 대한 정보만 이용했을 때보다 vision에 관한 정보를 이용했을 때 그 성능이 더 높아진 것을 볼 수 있습니다. 하지만, 그림8에서 ‘Text only’처럼 문자에 대한 정보를 사용했을 때보다 'Text + Layout + Image’처럼 vision에 대한 정보를 사용했을 때 그 차이가 크지 않아 vision에 대한 정보가 그렇게 중요하지 않다고 생각할 수 있습니다. 그렇지만, LayoutLM은 그림을 그대로 잘라서 넣었을 뿐 정보를 잘 추출하기 위한 전처리작업을 실행하지 않았기 때문에 vision에 대한 정보를 입력으로 더 잘 넣는다면 성능이 더 높아질 수도 있습니다.
3. 결론
지금까지 Document Understanding에 관한 연구들을 살펴 봤습니다. 4가지 연구 모두 문서에 적혀있는 텍스트의 의미 뿐만 아니라 문서가 제공하는 2차원적 정보도 사용하기 위해 문서의 이미지를 가공했는데요. 여기서 앞선 3가지 연구는 각 텍스트의 위치 정보를 제공하기 위해 문서 자체를 벡터로 치환했지만, 마지막 연구인 LayoutLM에서는 위치정보를 효과적으로 제공하기 위해 문서 자체를 치환하는 대신 위치 정보를 그대로 입력으로 넣어 주었습니다. 또한 텍스트 크기나 서체 등 vision 정보를 넣기 위해 텍스트 일부를 그림 그대로 잘라 입력으로 넣어줬고, 그 결과 다른 연구 대비 가장 높은 성능을 나타냈습니다. 이를 통해 Document Understanding에서는 문자와 vision에 대한 정보 모두 중요하다는 것을 알 수 있었습니다.
이렇게 인공지능을 이용해서 우리가 사용하는 문서, 영수증이나 invoice 등에서 필요한 정보를 추출하는 기술은 향후 여러 방면에서 활발히 사용될 것으로 기대됩니다. 작게는 일상생활에서 기록하는 가계부부터, 컴퓨터가 주로 사용되기 이전에 수기로 작성된 문서들의 디지털화 작업까지 다양한 분야에서 활용할 수 있을 것으로 보입니다.
참고문헌
[1] Katti, A. R., Reisswig, C., Guder, C., Brarda, S., Bickel, S., Höhne, J., & Faddoul, J. B. (2018). Chargrid: Towards understanding 2d documents. arXiv preprint arXiv:1809.08799.
[2] Denk, T. I., & Reisswig, C. (2019). BERTgrid: Contextualized Embedding for 2D Document Representation and Understanding. arXiv preprint arXiv:1909.04948.
[3] Zhao, X., Niu, E., Wu, Z., & Wang, X. (2019). Cutie: Learning to understand documents with convolutional universal text information extractor. arXiv preprint arXiv:1903.12363.
[4] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., & Zhou, M. (2019). LayoutLM: Pre-training of Text and Layout for Document Image Understanding. arXiv preprint arXiv:1912.13318.