“기사를 단 3줄로 요약해주는 AI”
안녕하세요, 오늘은 줌인터넷이 연합뉴스와 공동 개발한 AI 기반 ‘뉴스 세 줄 요약’ 서비스에 대한 연구 내용을 소개드리려고 합니다. 해당 서비스는 기사 요약 AI 기술이 국내 언론에 최초로 도입된 사례로, 현재 연합뉴스 홈페이지에서 확인할 수 있는데요. 지금부터 해당 연구 내용의 소개와 학습 데이터 구축 과정을 중점적으로 서비스 개발 과정을 설명드리겠습니다.
1. 연구 내용 소개
먼저 해당 연구는 자연어 처리(NLP) 분야 중 하나인 문서 요약(text summarization) 연구로 볼 수 있습니다. 문서 요약은 전체 문서에 포함된 글자와 문장들을 분석하여 요약문과 같이 글의 특징(feature)을 뽑아내는 주제입니다.
크게 추출적 방식(extractive approach)과 추상적 방식(abstractive approach), 두 가지 접근 방식이 주로 연구되고 있는데요. 추출적 방식은 입력으로 들어온 전체 텍스트에서 요약문에 해당하는 문장 혹은 문장의 위치를 추출하는 방식으로, 추출된 문장을 순서에 맞게 이어 붙여 간단하게 요약문을 생성해 낼 수 있습니다. 반면, 추상적 방식은 글의 내용을 파악하여 요약문에 해당하는 문장을 직접 생성하는 방식으로, 기존에는 구현 과정에서 어려움이 있었지만 최근 딥러닝 기술의 발전으로 다양한 연구 결과가 나오고 있습니다.
여기서 줌인터넷은 뉴스 문서가 가진 특성을 고려하여 추출적 방식을 활용해, 뉴스 문서 요약에 대한 연구를 진행했는데요. 뉴스 기사의 경우, 기타 블로그나 일반적인 웹문서와 비교해 다음과 같은 특징을 가지고 있습니다.
- 1) 전문 기자에 의해 육하원칙을 기반으로 기본 문서 형식이 갖춰진 형태로 작성됨
- 2) 기사 제목은 본문 내용의 주제를 대표하여 작성되며, 본문의 경우 내용 중복 없이 간결하게 표현됨
- 3) 사실에 기반한 정보를 제공하며, 문법적인 오류가 거의 없음
따라서 추출적 방식을 활용하면 뉴스 기사에서 주제에 가까운 문장들을 쉽게 찾아, 이 문장들을 연결해 요약 서비스를 구현할 수 있게 되는데요. 만약 추상적 방식을 활용하게 되면 생성된 문장에서 사용된 단어와 표현이 원문의 의도와 다르게 생성될 가능성이 있기 때문에, 추출적 방식을 선택해 연구를 진행하게 되었습니다.
2. 학습 데이터 구축 과정
1) 데이터 구축을 위한 전문인력 확보
일반적으로 딥러닝 연구에서는 양질의 데이터 구축을 가장 중요한 요소로 손꼽는데요. 이번 딥러닝을 이용한 뉴스 요약 기술 연구에서도, 모델 학습에 필요한 학습 데이터를 구축하는 과정을 매우 중요하게 고려하였습니다.
특히 학습 데이터(뉴스 요약문)의 특성 상, 사람에 따라 중요 문장을 선택하고 요약하는 방식이 다르기 때문에 양질의 데이터를 생성하기 위해서는 해당 데이터에 전문적인 지식을 가진 인력의 도움이 필요했습니다. 이처럼 주관적 판단이 필요한 학습 데이터의 경우, 해당 데이터에 대한 도메인 지식을 가진 전문 인력의 참여로, 높은 품질의 학습 데이터를 생성할 수 있는데요.
저희 연구팀은 양질의 데이터를 생성하기 위해, 지난해 3월부터 연합뉴스와 뉴스 데이터 및 태깅 업무에 대한 협업을 진행하였습니다. 이를 통해 전문 인력을 바탕으로 정해진 원칙(제목에 언급된 토픽을 다루는 문장을 선택)에 따라 검증된 품질의 태깅 데이터를 확보하여 모델 학습에 활용할 수 있었습니다.
2) 효율적인 데이터 구축을 위한 태깅툴 개발
뉴스 문서 요약을 위한 태깅 작업은 주어진 뉴스 기사를 사람이 하나하나 읽고, 해당 뉴스를 대표할 수 있는 문장들을 선택해 중요도 정보를 함께 입력하는 과정을 거쳐 진행되었습니다. 이처럼 학습 데이터 생성을 위한 태깅 작업은 사람이 수작업으로 진행되기 때문에 많은 시간과 노력이 요구되는데요. 태깅 작업에 사용하는 태깅 툴의 기능에 따라서도 작업의 효율성이 많이 달라질 수 있습니다. 좋은 태깅 툴을 선정하는 것은 빠른 작업 속도와 보다 정확한 정보 입력을 위해 중요한 일인데요.
태깅 툴을 제작하는 것 또한 시간과 노력을 들여야 하는 일이기 때문에 초기에는 오픈 소스로 공개된 프로그램을 찾아서 활용하도록 하였습니다. 인터넷상에 공개된 오픈 소스 태깅 툴도 적지 않은 수를 찾아볼 수 있는데, 쉽게 가져다 활용할 수 있는 반면 원하는 기능을 추가하기 위해서는 생각보다 많은 노력을 요구하는 경우가 많습니다. 이번 작업에서도 초기에는 오픈 소스 문서 태깅 도구인 Doccano를 설치하여 학습 데이터 생성 작업을 진행하였지만, 뉴스의 제목을 별도로 표시할 수 없는 등 필요한 기능이 충분하지 않고 사용자 인터페이스(UI)가 직관적이지 않아 뉴스 기사를 읽고 핵심 문장을 찾아 선택하여 입력하는 일련의 작업에 시간과 노력이 많이 요구된다는 문제가 있었습니다. 이러한 이유로, 보다 효율적이고 정확한 데이터 생성 작업을 위해 뉴스 요약문 선정을 위한 태깅 툴을 직접 제작하여 활용하게 되었습니다.

태깅 툴을 자체 제작하기로 결정하면서 가장 중요하게 고려한 사항은 1)주어진 뉴스 기사의 내용을 한 눈에 쉽게 이해하고, 2)선택 문장을 지정하고 이를 수정하는데 최소한의 노력만 필요하도록 설계한 것이었습니다. 우선 뉴스 기사는 인터넷 뉴스 페이지에서 노출되는 것과 같은 형태로, 이미지 및 단락 정보 등을 그대로 노출하여 기사의 내용을 보다 편하게 읽고 정확히 파악할 수 있도록 하였습니다. 또한 문장 선택 시 Doccano에서처럼 마우스를 드래그하여 처리하는 번거로움을 없애기 위해 주어진 뉴스 기사의 문장을 자동으로 분리해, 분리된 문장 단위로 마우스에 반응하도록 UI를 구성해, 단순한 클릭 한두 번으로 원하는 문장을 지정하고 수정할 수 있도록 하였습니다. 문장을 자동으로 분리하는 과정은 자연어 처리 기술을 활용하였고, 뉴스의 본문 내용과 관련이 없는 기타 정보들(기자/언론사명, 저작권 등 부가 문장)을 판별하여 제외하는 작업도 함께 진행하였습니다.
이렇게 뉴스 요약 문장 선별 작업에 최적화된 형태의 태깅 툴 개발을 통해 태깅 작업에 소요되는 시간을 상당히 단축시킬 수 있었고, 태깅 작업자의 만족도 또한 올라가 더 나은 품질의 학습 데이터를 구축할 수 있었습니다. 학습 데이터 생성을 위한 태깅 툴의 역할은 단순히 대상 데이터를 보여주고 태깅 정보를 입력받는 것에서 발전하여, 작업자에게 더욱 적합한 정보를 제공하고 단순 반복 작업을 최소화할 수 있는 기술적 지원까지 고려되어야 합니다. 또한 데이터 태깅 작업에 필요한 도메인 지식이 서로 다른 작업자 간에 태깅 결과물의 편차가 크지 않도록 보완하는 역할도 중요합니다.

3) 데이터셋의 특성
구축한 뉴스 요약 데이터셋은 정치, 경제, 사회, 연예, 국제, 스포츠, IT 등 총 8개 카테고리의 뉴스 데이터로 구성되었습니다. 해당 데이터셋은 기존 추출식 요약 데이터셋(CNN/Daily News)과 달리, 뉴스 기사의 제목을 포함하여 뉴스의 본문의 주요 문장을 판단하는데 있어 활용도가 높은데요. 기존 모델이 제목의 미포함 문제로 인해 오직 본문들 간의 관계를 모델링하여 요약문을 생성해 내야 하는 한계를 해결했다는 점에서 의의가 있습니다. 이 데이터셋을 활용하면 요약문을 추출함에 있어 제목과 본문 문장 간의 관계까지 함께 모델링해, 제목에 담긴 뉴스의 핵심 주제를 공유하는 요약문을 선정하는 데 있어 더 유리할 수 있습니다. 이를 통해 전통적인 추출식 모델처럼 본문만 이용하여 요약문을 추출하는 모델을 학습시키거나, 혹은 제목까지 추가로 고려한 요약물 추출 모델을 학습시킬 수 있습니다.
추출식 요약 모델을 위한 데이터셋이기 때문에 정답 라벨은 문장이 아닌 요약문에 선정될 문장의 위치(인덱스)로 주어졌고, 기사당 최대 3개의 요약문 위치가 학습을 위한 정답 데이터로 주어졌습니다.
실제 데이터셋을 구성하는 기사당 문장 개수 분포를 살펴보면 평균적으로 15.9문장을 가지며, 최소 1문장부터 최대 156문장까지 길어질 수 있음을 볼 수 있는데요.
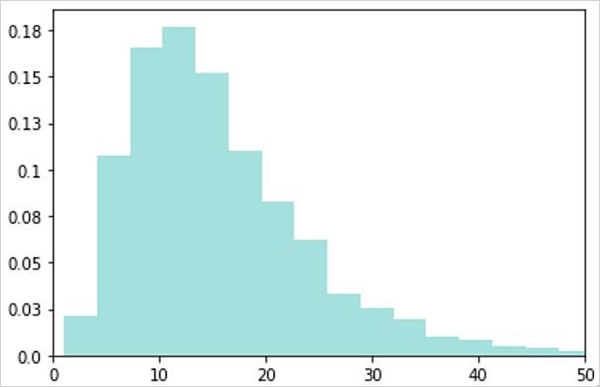
하지만, 두괄식으로 서술되는 기사의 특성상 정답 인덱스는 10을 넘어가는 경우가 거의 없음을 알 수 있습니다.

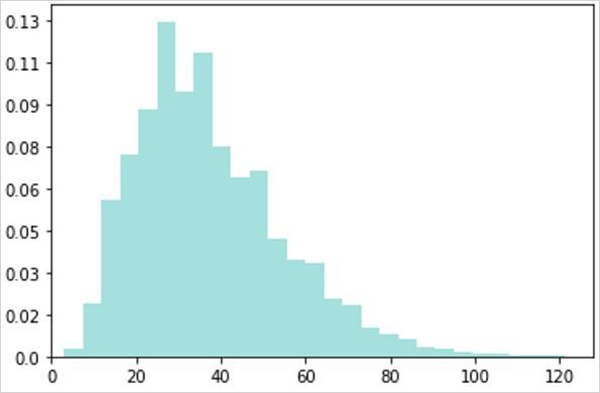
WordPiece Tokenizer를 이용한 토큰화 결과 뉴스 기사를 구성하는 문장의 토큰 수 분포는 평균적으로 37.3개이며, 17.4의 표준편차를 가지고 있는데요. 기사당 평균 문장 개수는 약 16개이기 때문에 문서당 평균 592개의 토큰을 가짐을 알 수 있습니다. 따라서 일반적인 트랜스포머 기반의 언어 모델을 이용하는 경우, 512개 이후의 토큰을 제거하거나 더 넓은 범위의 입력을 고려하고 싶은 경우엔 슬라이딩 윈도우 기법을 사용할 수 있습니다.
3. ‘세 줄 뉴스 요약’ 기술 개발 과정
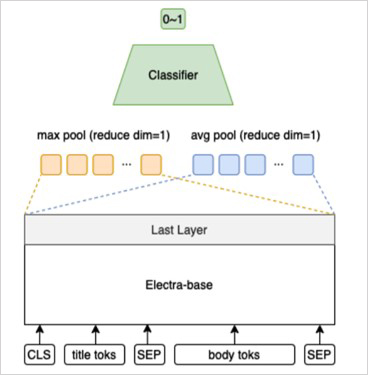
줌인터넷에서는 해당 데이터셋을 활용하여 추출 방식의 ‘세 줄 뉴스 요약’ 기술을 구현하였습니다. 이 데이터셋은 앞서 언급했던 것처럼 일반적인 텍스트 요약셋과는 달리 요약 대상 글(뉴스 기사)의 제목을 포함한다는 특성을 가지고 있는데요. 제목과 본문의 문장을 동시에 고려하여, 제목에 드러난 토픽을 잘 표현하는 문장으로 구성된 요약문이 사용될 수 있도록 모델 학습을 진행하였습니다.
트랜스포머 기반의 프리트레인(pre-train) 모델에 요약문 포함 여부의 분류를 위한 레이어를 추가하여, 제목 토큰과 문장 토큰을 모델의 입력으로 넣었을 때 그 결과를 0과 1 사이의 값(확률)으로 출력하도록 학습시켰습니다. 이때 프리트레인 모델로는 구글의 ELECTRA를 사용했으며, 뉴스 본문을 구성하는 문장들에 대한 각 확률(스코어)를 얻고, 확률이 가장 높은 순으로 k개의 문장을 추출함으로써 요약문이 구성되도록 설계하였습니다. 자세한 모델 구현 과정은 아래 <그림7>과 같습니다.
이를 바탕으로 현재 줌인터넷은 연합뉴스 홈페이지 내 하루 평균 900여 건의 기사에 대해 실시간 요약 서비스를 제공하고 있습니다. 다만, 사진, 영상기사, 인사 및 부고 등 요약할 필요가 없거나, 3문장 이하의 짧은 기사에는 해당 서비스가 적용되지 않고 있습니다.
4. 향후 연구방향
앞서 소개한 연구 과정을 거쳐 개발된 문장 단위(Sentence Level)의 추출식 요약 모델은 현재 연합뉴스의 세 줄 요약 서비스로 활용되고 있는데요. 해당 서비스는 API 형태로 개발되어 손쉽게 관리 및 활용 가능하다는 이점이 있기 때문에 향후 다양한 방식으로 활용도 기대하고 있습니다.
현재 줌인터넷 연구팀은 요약문의 품질을 향상시키기 위해, 요약문 단위(Summary Level)의 추출식 요약 모델에 대한 연구를 진행하고 있습니다. 요약문 단위 추출식 요약 모델은 앞서 개발된 문장 단위의 추출식 요약 모델을 이용하여 주요 문장을 얻고, 주요 문장을 조합하여 여러 개의 후보 요약문을 생성한 뒤, 후보 요약문 중에서 요약문으로써 가장 적합한 요약문을 선택하는 방식으로 구현되는데요. 추출식 요약 모델의 부산물로서 주어지는 문서의 문장 단위 주요점 맵(Saliency Map)은 문서 요약이 아닌 다른 문제 해결을 위한 사전 정보로서 활용 될 수 있기 때문에 향후 이 정보들을 활용하여 기술 고도화에 힘쓸 예정입니다.
또한, 추출식 접근법은 문장 사이의 연결이 매끄럽지 못하거나, 모든 문장이 요약문으로 적합하지 않을 경우에는 낮은 품질로부터 벗어나기 힘든 단점이 있는데요. 이를 해결하기 위해 추상적 방식의 접근법을 이용해서 요약문 생성 모델에 대한 연구도 향후 진행할 예정입니다.
앞으로도 줌인터넷의 AI 기술 연구 및 서비스에 많은 관심과 성원 부탁드립니다. 감사합니다.
참고문헌
[1] Get To The Point: Summarization with Pointer-Generator Networks (https://arxiv.org/abs/1704.04368)
[2] ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
(https://arxiv.org/abs/2003.10555)
[3] Extractive Summarization as Text Matching
(https://arxiv.org/pdf/2004.08795.pdf)
[관련 포스팅 보러가기] ‘가짜뉴스를 찾아라!’ 가짜뉴스 판별 특허 알아보기 딥러닝 기반 연예뉴스분석시스템 개발기