딥러닝계에서는 ImageNet Moment란 말이 있다. 2012년 Convolutional Neural Network이 ImageNet Challenge에서 2등과 엄청난 격차로 우승을 한 사건을 말한다. 이 시점 이후, 이미지 인식에 딥러닝을 쓰는 것은 필수가 되었고 학계에서만 연구되던 딥러닝이 산업에 본격적으로 쓰이기 시작하였다. 특히, 인공지능이 우리의 삶을 바꿀 수 있다는 기대감이 뿌리내리는 계기가 되었다.
BERT란 무엇인가?
그로부터 6년 후인 2018년, Google은 BERT(Bidirectional Encoder Representations from Transformers)라는 모델을 선보이며 NLP의 ImageNet Moment를 열었다 [1]. 이 모델은 11개의 NLP Tasks의 성능을 바탕으로 모델들의 순위를 매기는 GLUE (General Language Understanding Evaluation) Benchmark에서 다른 모델들을 큰 차이로 앞서며 최고 성능을 보여주었다 [2]. 또한, 가장 인간다운 자연어 이해를 기반으로 한 자연어 질문에 대한 답변을 해야하는 태스크 SQUAD(The Stanford QUestion Answering Dataset) Benchmark에서 기존 최고 성능을 깨면서 주목받기 시작하였다 [3]. 실제로 이때부터 거의 모든 NLP Benchmarks에서 BERT를 이용하거나, 개선한 모델들(XLNet, RoBERTa, ALBERT, …)이 상위권을 점유하기 시작하였다.

BERT는 Transformer를 기반으로 Sentence Embedding 혹은 Contextual Word Embedding을 구하는 네트워크로, 문장을 토큰으로 쪼개서 네트워크에 넣으면 전체 문장에 대한 Vector와 문장안의 각 단어(정확히 말하면 토큰) 각각에 대응되는 Vector를 출력한다. 이들을 기반으로 Text Classification등의 Task를 학습하여 수행하면 매우 쉽게 뛰어난 성능을 얻을 수 있는데, 이는 전체 네트워크가 매우 많은 양의 문서로 Masked Language Models을 미리 학습(pre-training)하였기 때문이다 [4]. (자세한 사항은 논문을 참조)

챗봇에서의 머신러닝 활용
챗봇(Dialog Systems)도 BERT의 바람을 피해가지는 못하였다. 여기서는 특히, 인공지능 스피커에서 주로 이용되는 기능수행 챗봇(Task-Oriented Dialog Systems)중에서 Dialog State Tracking에 대해서만 알아보기로 한다.
이 시스템은 사용자가 얘기한 문장이 어떤 의도인지 알아내는 Intent Classification과 그 문장이 구체적으로 어떤 요청인지 알아내는 Slot Filling으로 구성되어 있다. 예를들어 사용자가 "예술의 전당까지 가는 택시 좀 불러줘" 라고 말한다면, 챗봇은 이 문장의 의도가 "택시호출"이라는 것과 "목적지(slot)=예술의 전당(value)" 임을 알아야 택시 호출 API를 통해 정확한 서비스콜을 할 수 있는 것이다.

기존의 시스템은 이를 인식하기 위해 각각의 문장 분류(Classification) 모델을 학습하였는데, 즉, 어떤 문장이 <택시호출, 목적지, 예술의 전당> 쌍에 해당하는지를 각각 따로따로 학습하는 것이다. 만약 강남구의 레스토랑을 예약하는 문장을 인식하고 싶다면, <레스토랑-예약, 지역, 강남구>에 해당하는 분류 모델을 학습하여야 한다.
여기서 몇가지 문제가 생기는데, 하나는 챗봇이 어떤 유형의 문장들을 인식하여야 하는지, 즉, <택시호출, 목적지, 예술의 전당>, <레스토랑-예약, 지역, 강남구> 등을 미리 정의해놓아야 한다는 것이다. 이를 정의한 문서를 Ontology라고 하는데, 문제는 이것이 서비스 중에 업데이트 될 수 있다는 것이다. 원래는 서울 이외의 지역을 가지 않기로 한 택시호출 서비스가 어느날 경기도까지 서비스하기로 결정하였다면, <택시호출, 목적지, 정자역>에 해당하는 문장도 인식해야한다. 근데 그러려면 이에 해당하는 문장을 다시 준비를 해서 학습을 해야하기때문에 업데이트를 하는데 시간이 꽤 걸리게 된다. 더욱이 목적지에 해당하는 값은 매우 많으므로 (예술의 전당, 정자역, 시청, 용산역, 검찰청, ...) 각각의 조합에 각각의 분류 모델을 따로 학습해서 서비스를 하는 것은 각각의 데이터를 따로 구해야 하는 어려움이 있으며, 학습/추론 시간도 매우 오래 걸릴수가 있다. 즉, 기존의 시스템은 확장성(scalability)이 떨어진다고 할 수 있다 [7].
BERT를 활용한 확장성있는 챗봇만들기
CMU의 연구자들은 이를 타개하기위해 BERT를 Dialog State Tracking에 도입하였다 [8]. 이는 BERT 활용의 한 사례인 Span Prediction을 이용하였다. 문장을 BERT에 넣고 문장 전체의 의미를 담고 있는 첫번째 Vector를 이용해서 각 Slot이 해당사항이 없는지(None), 어떤 값이든 상관 안하는지(Don’t Care), 사용자의 얘기에 Slot Value가 존재하는지(Span)를 예측한 후에, 각 토큰의 해당하는 Vector들을 이용하여 Slot Value의 시작점에 대한 확률과 종료점에 대한 확률을 계산하고 이를 바탕으로 Slot Value를 추측하게 된다.
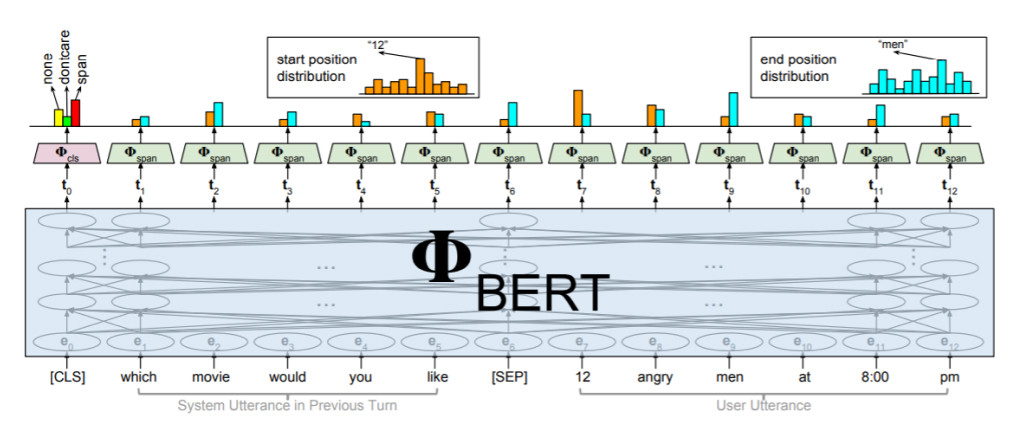
이렇게 되면 최소한 Slot의 Value들을 미리 알고 있지 않아도 된다. 즉, <택시호출, 목적지, 예술의 전당>에서 "예술의전당"이라는 목적지는 미리 알지 못해도 사용자의 얘기에서 추출할 수가 있으므로, <택시호출, 목적지>에 해당하는 모듈만 따로 학습해놓으면 된다. 이는 서울 지역만 가는 택시호출 서비스가 설령 서울 이외의 지역으로 가게 되었다 하더라도, 새로 시스템을 업데이트할 필요가 없다는 것을 뜻한다. 이 모델은 Slot Value들을 미리 알지 못한 상태에서 동작함에도 불구하고, WOZ 2.0 데이터셋에서 최고 성능에 가까운 성능을 얻어서 BERT의 강력함을 보여주었다.
처음보는 서비스도 처리할 수 있는 챗봇
여기서 한발 더 나아가, BERT의 언어처리 능력을 활용하면 아예 처음보는 서비스나 Slot의 경우에도 처리할 수 있는 Zero-shot Learning이 가능하다. 특히 최근 광범위하게 퍼지고 있는 Voice Assistants(인공지능 스피커)의 경우에는 수많은 서비스들이 꾸준히 추가되고 있는데, 이때마다 다시 학습이 필요하다면 매우 번거로운 일이 될 것이다. 하지만 실상 비슷한 의미의 Slot이 추가되는 경우, 인식하는 방식이 비슷함에도 불구하고 기존의 시스템에서는 따로 학습을 해야했다. 예를들면 비행기 예약 서비스에서의 "예약 시간"과 기차 예약 서비스에서의 "예약 시간"을 인식하는 시스템은 거의 같은 의미임에도 불구하고, 서비스가 다르기 때문에 따로 학습을 해야했었다. 그치만 Slot의 설명(Schema)이 주어진다면 BERT의 언어처리 능력을 통해 이것이 기존의 Slot과 비슷하다는 것을 시스템이 인지할 수 있으므로, 기존에 학습된 모델을 활용해서 새로운 데이터 없이도 (완벽하지는 않지만) 처리가 가능할 것이다.
최근 구글에서는 BERT를 활용해서 이와 같은 Zero-shot Learning이 가능한 모델을 발표했다 [9]. 다음의 두 비행기 예약 서비스를 보자.
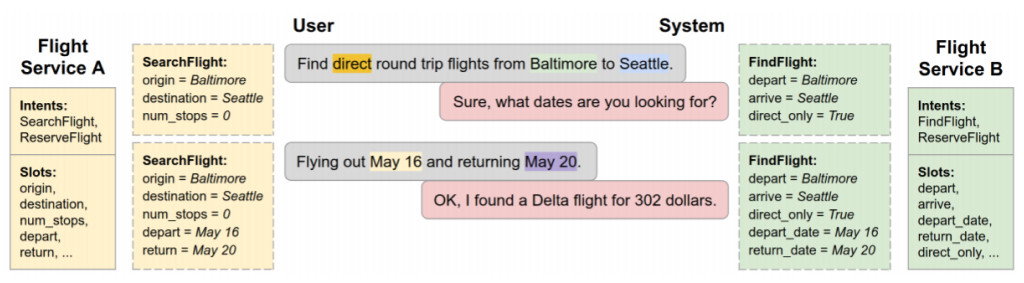
이해를 돕기위해 Flight Service A는 대한항공, Flight Service B는 아시아나라고 해보자. 대한항공에서 비행기 검색 의도는 SearchFlight이라고 정의되고, 아시아나에서는 FindFlight라고 정의된다. 실상 이들이 하는 일은 거의 같지만, 기존의 시스템에서는 이들은 엄연히 다른 서비스에 속해있는 것이므로 따로 다른 데이터를 가지고 학습을 하게 된다. 만약 이 의도들의 설명이 주어지고, BERT가 이 두 설명이 비슷하다는 것을 알려준다면, 대한항공 서비스를 위해 이미 학습이 끝난 모델을 거의 그대로 아시아나 서비스를 위해 사용할 수 있을 것이다.
Slot의 경우도 마찬가지인데, origin과 depart, destination과 arrive는 사실 같은 의미이므로 각각 설명들에 대한 BERT의 출력(embedding)을 이용하면 이들이 같은 의미를 가진다는 것을 알 수 있고, 아시아나 서비스에 대한 학습은 전혀 없는 상태에서도 대한항공만큼의 인식률을 바로 얻을 수 있을 것이다. 이는 각 Intent혹은 Slot에 대한 설명(Description)을 BERT에 입력해 얻은 Vector를 앞에서 언급한 Slot Value Span Prediction에 같이 사용함으로써 가능하다. 구글은 이 모델을 통해 학습 데이터셋에 존재하지 않는 Unseen Service에 대해서도 높은 인식률을 얻었다.
챗봇의 미래
사실 현재의 챗봇은 정말 사람처럼 대화하는 수준에는 전혀 미치지 못하고 있어, 큰 기대감에도 불구하고 그 활용성이 매우 제한되고 있다. 그렇다면 과연 BERT가 챗봇 업계의 구세주가 될 수 있을까? 물론 BERT가 기존 모델대비 강력한 자연어 이해 능력으로 이후에도 챗봇에 크게 기여할 것으로 보인다. 하지만 챗봇이 사람처럼 미묘한 맥락을 파악해서 다양하고 풍부한 대화를 할 수 있으려면, 아직도 많은 혁신이 필요해보인다. BERT는 그 첫 걸음일 뿐이다. 향후 어떠한 혁신이 또 이루어질지 설레는 마음으로 지켜보려 한다.
참고문헌
[1] Sebastian Ruder, NLP's ImageNet moment has arrived. (2018) https://thegradient.pub/nlp-imagenet/
[2] Alex Wang et al, GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding (ICLR 2019)
Paper: https://arxiv.org/abs/1804.07461, Site: https://gluebenchmark.com/leaderboard
[3] Pranav Rajpurkar et al, Know What You Don’t Know: Unanswerable Questions for SQuAD (ACL 2018) Paper: https://arxiv.org/abs/1806.03822, Site: https://rajpurkar.github.io/SQuAD-explorer/
[4] Jacob Devlin et al, BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding (NACCL 2019) Paper: https://arxiv.org/abs/1810.04805, Github: https://github.com/google-research/bert
[5] Jay Alammar, The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) (2018) http://jalammar.github.io/illustrated-bert/
[6] PolyAi, Deep Learning for Conversational AI (NAACL 2018 Tutorial) https://poly-ai.com/naacl18
[7] Nikola Mrksic et al. Neural Belief Tracker: Data-Driven Dialogue State Tracking (ACL 2017) Paper: https://arxiv.org/abs/1606.03777
[8] Guan-Lin Chao, BERT-DST: Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer (INTERSPEECH 2019) Paper: https://arxiv.org/abs/1907.03040
[9] Abhinav Rastogi et al, Towards Scalable Multi-domain Conversational Agents: The Schema-Guided Dialogue Dataset (2019) Paper: https://arxiv.org/abs/1909.05855