본 글은 최신 AI 연구 트렌드를 살펴보기 위해 NeurIPS 2019를 통해 발표된 논문의 통계를 분석한 글입니다. 논문 내용 자체가 아닌, 게재 논문 수의 변화, 최빈 단어 등의 통계치를 분석했습니다.

1. NeurIPS의 시작과 현재
올해 34번째 개최를 앞둔 NeurIPS(Neural Information Processing Systems, 신경정보처리시스템학회)는 현재 'ICML', 'ICLR'*과 함께 세계 최고 권위의 인공지능 학회로 손꼽히는데요. 1987년 벨 연구소(Bell Labs)와 캘리포니아공대(Caltech)의 공동 주도 하에 'NIPS'라는 이름으로 시작되었고, 지난 2018년에 정식 명칭이 'NeurIPS'로 변경되었습니다.
* ICML(International Conference on Machine Learning, 기계학습국제학회), ICLR(International Conference on Learning Representation, 표현학습국제학회)
첫 컨퍼런스인 'NIPS 1987'에서 게재 논문 수는 90편으로 규모가 그리 크지 않았지만, 2016년부터는 발표 논문 수가 급격히 증가(그림1)하고 있습니다. 특히 지난 2019년 12월 캐나다 밴쿠버에서 개최된 'NeurIPS 2019'에서는 deep learning, reinforcement learning, probabilistic methods, biology 등 매우 다양한 분야에서 무려 1428편의 논문이 발표되었습니다.
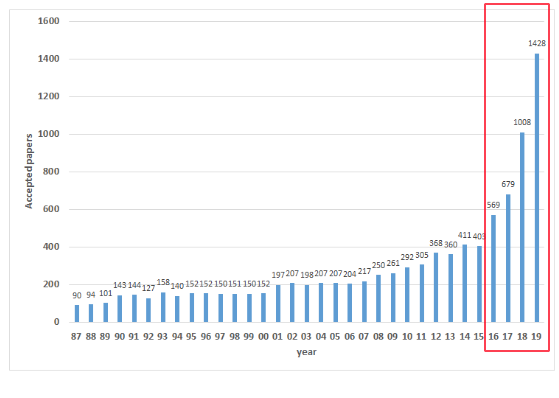
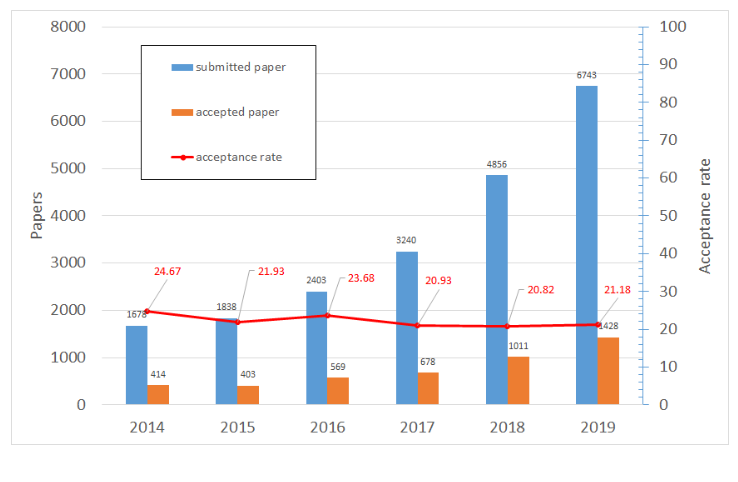
반면, acceptance rate는 여전히 20~24% 사이를 유지(그림2)하고 있습니다. 즉, 게재되는 논문들의 퀄리티는 높게 유지되고 있다는 것입니다. 이와 같이 높은 퀄리티의 논문이 급격하게 증가하게 된 것은 AI에 대한 관심과 이를 받쳐줄 수 있는 하드웨어 및 인프라 발달 덕분이라고 할 수 있습니다. 인공지능에 대한 학계의 높은 기대치로 봤을 때, 향후 게재 논문 수는 훨씬 더 증가할 것으로 예상됩니다.
2. NeurIPS 2019 게재 논문 수 분석
2010년 중반 이후로, 학교나 기업 등 기관 종류를 가리지 않고 다양한 곳에서 굉장히 많은 AI 관련 연구가 이루어지고 있습니다. 어떤 기관이 가장 활발한 연구 활동을 하고 있는지 NeurIPS 2019를 통해 알아보기 위해 총 1428편의 NeurIPS 2019 accepted paper에서 기업과 학교 이름을 파싱하여 분석하였습니다.
한 논문 내에서 저자들의 소속 기관이 모두 같을 경우 하나의 기관으로 카운트 하였고, 소속 기관이 여러개일 경우 각 기관마다 카운트 하였습니다. 또한, [Google, google brain, google research], [microsoft, microsoft research] 등과 같이 모기업이 같은 여러 기관의 경우엔 모기업의 이름으로 통일하였습니다.
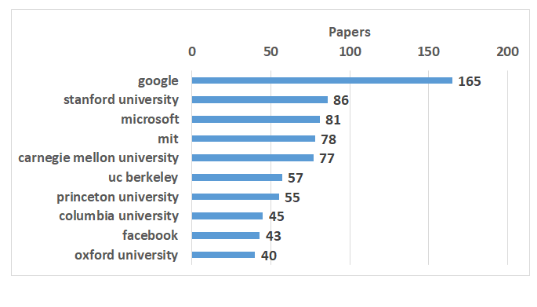
그 결과, google이 총 165편으로 가장 활발한 연구 활동을 하고 있었습니다. 2~4위를 차지한 기관이 각각 86편, 81편, 78편을 제출한 것을 감안하면 NeurIPS 2019에서 google의 논문 제출 수는 가히 압도적이라 할 수 있습니다. google 외 기업 으로는 microsoft(81편), facebook(43편) 등이 많은 연구를 하고 있었고, 학교로는 stanford university(86편), MIT(78편), carnegie mellon university(77편) 등이 많은 연구를 하고 있었습니다.
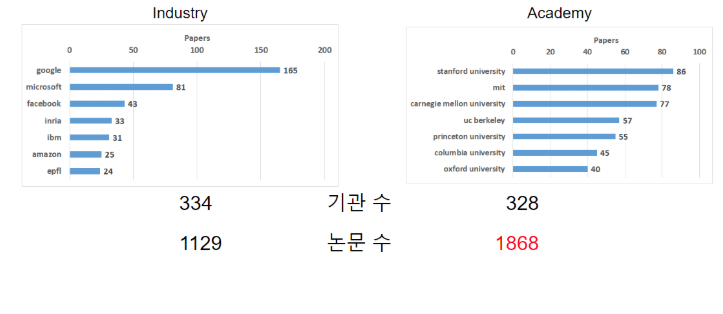
여기서 기업과 학교의 수를 분리하여 비교해 보았습니다. 그 결과, 총 기관 수는 약 330개 전후로 비슷했지만, 논문 수는 학교(1868편)가 기업(1129편) 대비 약 65% 많음을 알 수 있었습니다. (그림4)
기업의 경우, 앞서 언급한 것처럼 google이 압도적으로 많은 연구 활동을 하고 있었고, microsoft, facebook, inria, ibm, amazon등의 기업이 그 뒤를 따라가고 있었습니다. 학교의 경우 stanford와 MIT, CMU가 가장 많은 연구 활동을 하고 있었고, uc berkeley, princeton, columbia, oxford 등이 그 뒤를 따라가고 있었습니다.
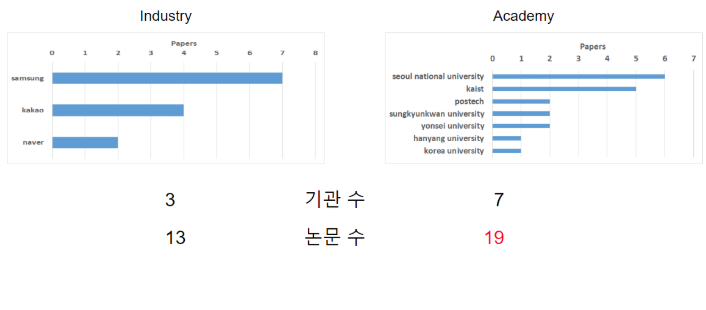
이번에는 국내로 한정지어 살펴보겠습니다. 최근 국내 기업과 학교도 AI 관련 연구를 굉장히 활발하게 하고 있지만, 아직 외국에 비해 논문 수는 많이 부족한 편입니다. 국내의 경우에도 외국과 마찬가지로 기업보다 학교의 논문수가 더 많았습니다. 국내 기업으로는 samsung(7편), kakao(4편), naver(2편) 등 3개 기업의 논문이 accept 되었고, 학교로는 서울대(6편), 카이스트(5편), 포항공대(2편), 성균관대(2편), 연세대(2편), 한양대(1편), 고려대(1편) 등 7개 학교의 논문이 accept 되었습니다.
3. NeurIPS 최빈 단어 분석 결과
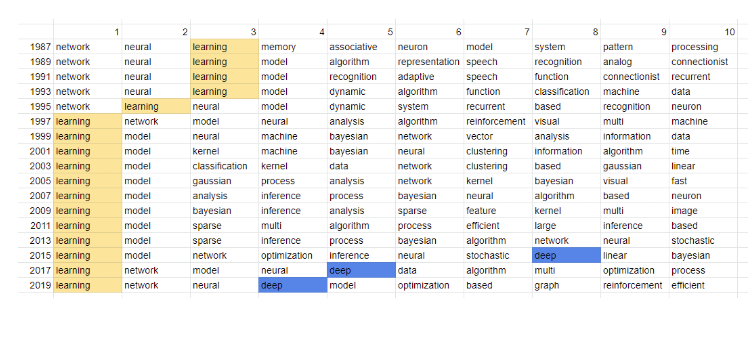
NeurIPS를 통해서 매년 폭넓은 범주의 논문이 발표되고, 해마다 유행하는 분야가 조금씩 달라지고 있습니다. 어떤 유행이 있었는지 살펴보기 위하여 NeurIPS 1987~2019 의 accepted paper title 을 parsing하여 자주 등장하는 단어를 분석하였습니다.
분석 결과는 그림 6과 같습니다. 그림 6에서 각 행은 NeurIPS의 개최년도(2년 단위)를 나타내고, 각 열은 자주 등장하는 단어를 나타내고 있습니다. NeurIPS가 처음 개최된 1987년부터 1993년까지는 NeurIPS의 취지에 걸맞게 ‘network’, ‘neural’, ‘learning’ 세 단어가 가장 자주 등장하였습니다. 이 세 단어는 1993년 이후에도 꾸준히 최상위권을 차지하고 있었으며, 특히 ‘learning’은 1997년부터 현재까지 가장 자주 등장하는 단어였습니다. ‘deep’ 은 2010년 초반에 처음 등장하여 2015년부터 순위권에 들어가기 시작했습니다. 그 이후로는 그 순위가 급격히 상승하여 2019년에는 4위를 차지하였습니다. 이를 보아 딥러닝에 대한 관심이 아주 높아지고 있다는 것을 알 수 있습니다.
추가적으로, 연도별 주요 단어가 차지하는 비율 변화를 분석하였습니다. NeurIPS의 논문 수가 계속 늘어나고 있으므로, 전체 단어 수도 자연히 늘어나게 됩니다. 따라서, 단어의 총 갯수를 보지 않고 전체 단어 중 차지하는 비율을 분석하였습니다. 분석 대상 단어는 NeurIPS 1987~2019에서 자주 등장하는 8개의 단어로, ‘network’, ‘neural’, ‘bayesian’, ‘reinforcement’, ‘deep’, ‘algorithm’, ‘learning’, ‘model’ 입니다.
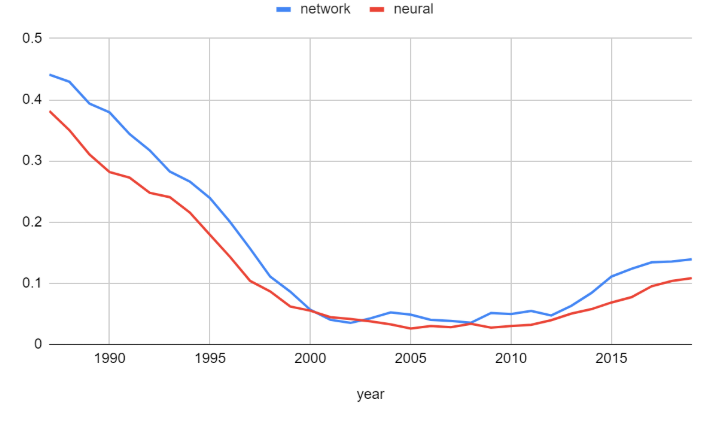
- 분석 대상 단어: network, neural
NeurIPS 초반에는 ‘network’, ‘neural’ 두 단어의 비중이 약 40% 정도로 굉장히 높았습니다. 즉, 대부분의 논문에서 두 단어를 사용한 것입니다. 하지만 논문의 분야가 다양해지고, 신경망에 대한 관심이 줄어들면서 두 단어가 차지하는 비율도 점점 줄어들어 2010년 즈음에는 5%에 불과했습니다. 하지만, 이후 CNN이 등장함과 동시에 신경망에 대한 관심이 다시 높아지면서 2019년에는 10% 정도의 비율을 차지하였습니다.
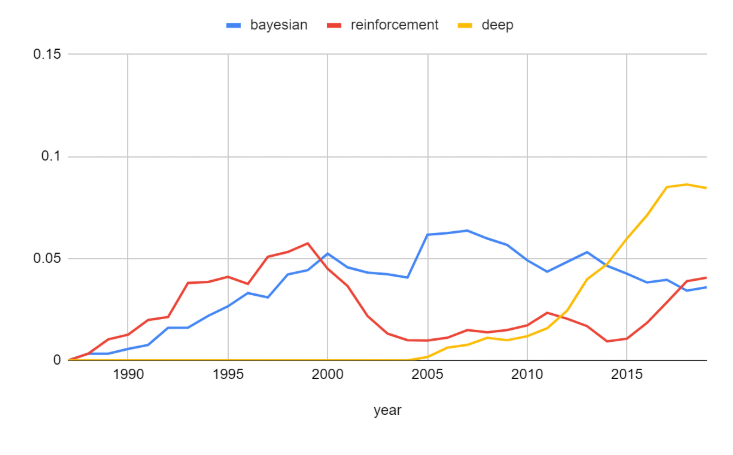
- 분석 대상 단어: bayesian, reinforcement, deep
‘bayesian’은 NeurIPS 초창기부터 등장하였으나, 그 당시엔 비율이 굉장히 낮았었습니다. 하지만 그 비율이 점점 높아져 2005년엔 5% 이상을 차지하였고, 그 이후로 꾸준히 5%를 유지하고 있습니다. 즉, 딥러닝 기술이 발전하더라도 고전적인 추론 방법이 외면받지 않고 꾸준히 연구되고 있으며, 앞으로는 두 가지 기술이 결합되는 형태의 기술이 많이 나올 것으로 예상됩니다.
‘reinforcement’는 1990년대 후반까지 자주 쓰이다가 2000년 중반에는 거의 쓰이지 않는 단어가 되었습니다. 하지만 알파고, 알파스타 등의 알고리즘들이 ‘reinforcement’를 사용하면서 높은 성능을 내는 등 최근 핵심 연구 주제로 거듭나면서 사용 빈도가 빠르게 증가하고 있습니다.
한편, ‘deep’은 NeurIPS 초창기에는 쓰이지 않던 단어였으나, 2000년대 초반에 처음 쓰이고 CNN이 등장 이후로 그 비율이 굉장히 가파르게 높아지고 있습니다. 이러한 추세는 당분간 계속될 것으로 생각됩니다.
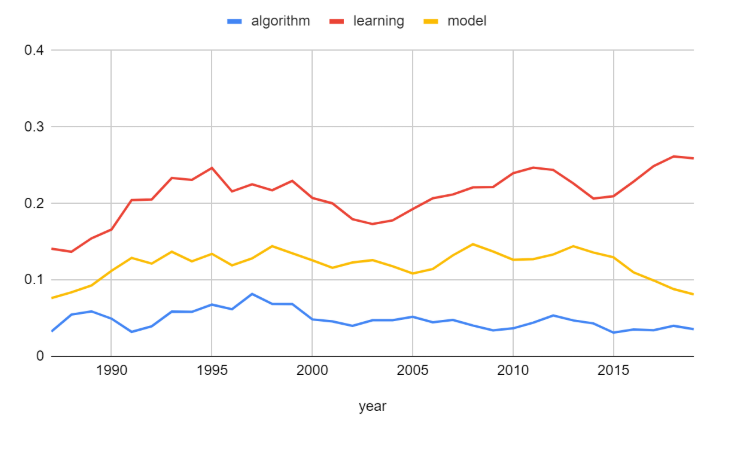
- 분석 대상 단어: algorithm, learning, model
‘algorithm’, ‘learning’, ‘model’은 머신 러닝 컨퍼런스인 NeurIPS의 특성에 맞게 초창기부터 지금까지 꾸준한 비율을 유지하고 있습니다. 즉, 고전적인 방법 또는 딥러닝을 이용한 방법 등 학습 방식의 변화는 있지만, 최적의 모델을 찾기 위한 연구는 꾸준히 진행되고 있음을 알 수 있습니다.
4. 결론
NeurIPS 2019를 통해 발표된 논문 수는 NeurIPS 2018 대비 약 1.4배 증가하였습니다. 그만큼 분야도 다양해지고, 머신 러닝의 적용 범위도 굉장히 넓어졌습니다.
이번 통계 분석 결과, 수많은 기업과 학교에서 AI 관련 연구를 진행하고, 기업보다는 학교에서 좀 더 많은 논문을 내고 있음을 확인할 수 있었습니다. 기업 중에서는 google, microsoft, facebook 등이, 학교 중에서는 stanford, MIT, CMU 등이 활발한 연구를 진행하고 있었습니다. 아직까진 국내 논문 수가 그렇게 많지 않았으나, 점차 늘어날 것으로 예상됩니다.
또한, 딥러닝에 대한 관심이 높아짐에 따라 neural, deep, network 등의 단어가 점점 더 논문에 자주 등장하고 있으며, 머신러닝 컨퍼런스의 취지에 걸맞게 algorithm, learning, model 등의 단어는 큰 변화없이 꾸준히 자주 등장하고 있었습니다.
이를 통해 AI에 대한 기업과 학계의 관심은 여전히 높으며, 사람들의 기대치도 점점 높아지고 있음을 볼 수 있었습니다. 이러한 추세는 당분간 지속될 것으로 보이며, 올해는 또 어떠한 논문들이 나올지 기대가 됩니다.