안녕하세요, AI PLUS Tech Blog입니다. 오늘은 줌인터넷에서 등록한 가짜뉴스 관련 특허에 대해 간단히 소개드리려고 합니다.
1. 가짜뉴스란?
먼저 특허 내용을 소개하기 앞서, 특허가 나오게 된 배경인 ‘가짜뉴스’에 대해 알아보겠습니다. ‘가짜뉴스’라고 하면 어떤 뉴스가 떠오르시나요? 아마 아래 <그림1>과 같이 거짓으로 꾸며진 뉴스를 생각하실 것 같은데요!
이러한 뉴스는 출처가 불분명한 정보를 게재하는 형식으로, 어떠한 세력이 조작된 정보를 유포함으로써 이득을 얻기 위해 배포되는데요. 지난 미국 대선이나 코로나19 등 정치, 사회적 이슈와 관련된 거짓 정보들이 대량 유포되며 많은 논란이 되기도 했습니다. 쉬운 이해를 돕고자 실제 기사 예시를 첨부하려고 했지만, 그렇게 되면 저희 블로그가 특정 집단을 옹호하는 것처럼 보일 수 있어 적당한 사례를 작성해 보았습니다.
다만, 오늘 소개드릴 특허는 다양한 유형들의 가짜뉴스들을 보자마자 ‘아 이거 가짜네!’하고 밝히는 내용이 아닌, <그림2>와 같은 유형의 가짜뉴스를 판별하는 특허입니다. 어느부분이 가짜인지 여러분도 한 번 찾아보세요!

너무 쉬웠나요..? ‘알파고’는 당연히 이스트소프트에서 개발한 프로그램이 아닙니다. (구글에서 개발했죠) <그림2>와 같은 뉴스는 본문에는 등장도 하지 않은 알파고를 ‘알툴즈 프로그램’과 명칭적 유사성이 있다는 이유로, 제목에 추가하여 클릭을 유도하는 형식의 가짜뉴스입니다.
이번 포스팅에서는 이처럼 본문 내용과 관련이 없는, 조작된 정보를 기사 제목으로 제공하는 가짜뉴스를 판별하는 특허에 대해 소개하려고 합니다.
2. 특허 소개
오늘 소개드릴 특허의 제목은 아래와 같습니다.
“거짓된 기사 제목이 포함된 스팸뉴스 탐지를 위한 장치, 이를 위한 방법 및 이 방법을 수행하는 프로그램이 기록된 컴퓨터 판독 가능한 기록매체”(등록번호: 1021499170000)
공개된 특허 전문에 어떻게 표기되어 있는지 살펴보면, 아래 문단과 같이 요약할 수 있습니다. (먼저 얘기해드리자면, 아래 문단만 보고는 특허를 작성한 저도 꽤나 헷갈립니다. 이 문단을 자세히 이해하실 필요는 없으니, 특허는 다소 복잡하게 작성해야 되는구나~ 하고 넘어가주세요)
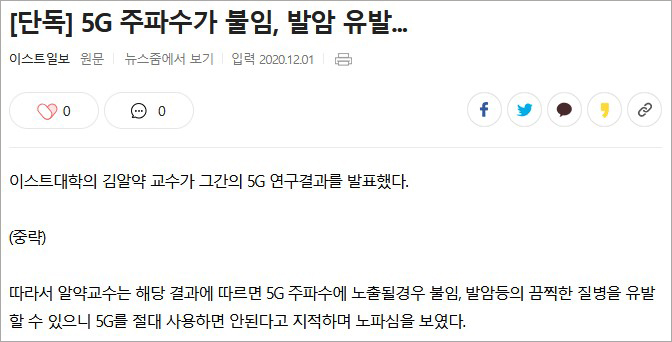
“상술한 바와 같은 목적을 달성하기 위한 본 발명의 바람직한 실시예에 따른 스팸 뉴스 탐지를 위한 장치는 제목과 본문으로 이루어진 뉴스 기사에서 상기 제목에 포함된 단어와, 상기 본문 중 상기 제목에 포함된 동일한 단어가 가장 많이 포함된 단락을 중요문단으로 도출하는 중요문단도출부와, 상기 중요문단에 포함된 단어가 상기 제목에 포함된 단어의 반의어일 확률을 나타내는 반의어 점수를 산출하는 반의어점수산출부와, 상기 제목에 포함된 명사 간의 거리 대비 상기 중요문단에 포함된 명사 간의 거리를 나타내는 거리 점수를 산출하는 거리점수산출부와, 상기 중요문단에 포함된 단어의 순서 대비 상기 제목에 포함된 단어의 순서가 도치되었을 확률을 나타내는 도치 점수를 산출하는 도치점수산출부와, 상기 반의어 점수, 상기 거리 점수 및 상기 도치 점수를 합산하여 최종 점수를 산출하고 상기 최종 점수에 따라 상기 뉴스 기사가 스팸 뉴스인지 여부를 결정하는 스팸뉴스판별부를 포함한다.”
물론, 이 블로그에서는 치사하게 특허 내용만 쓱 긁어 넣은채 넘어가지는 않고, 간단히 요약 설명을 덧붙이려고 합니다. 일단, 저 내용을 간단하게 도식화하면 아래 도면과 같이 나타낼 수 있습니다.
이렇게 나타내면 어떤 구조일지 조금은 이해가 가시나요? 먼저 가짜뉴스 탐색을 위해 본문 전체를 다 살펴볼필요는 없으니, 가장 중요하다고 생각되는 중요문단을 찾아냅니다. 그리고 해당 문단에서 스팸여부를 판별할 점수 3개(반의어, 거리, 도치점수)를 산출해내고, 통합된 점수를 바탕으로 스팸여부를 판별하는 구조입니다. 그럼 각 과정을 하나씩 살펴보도록 하겠습니다.
2.1. 중요문단 추출
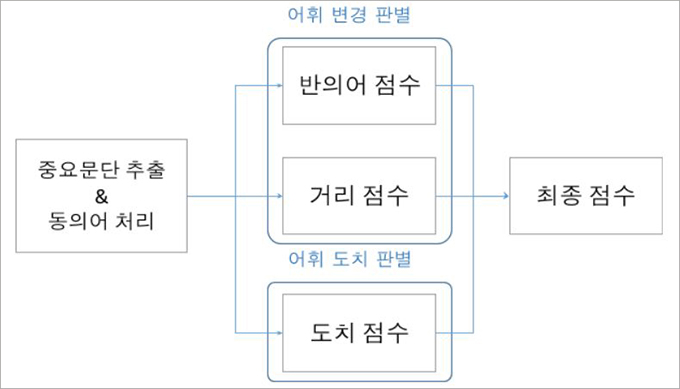
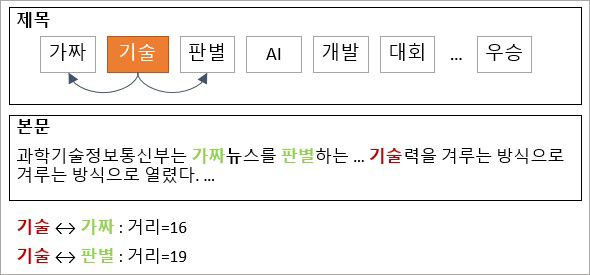
먼저 <그림3> 가장 왼쪽의 중요문단 추출과정은 아래 <그림4>와 같습니다. 제목에 포함된 단어와 본문 각 문단에 나타난 단어의 개수를 단순비교하여 가장 많은 단어를 포함한 문단을 ‘중요문단’으로 선별합니다.
그리고 제목과 중요문단을 비교해, <그림5>와 같이 제목에는 나와있지만 중요문단에는 나와있지 않은 단어를 선별합니다. 이 ‘중요단어’가 많을수록 해당 뉴스가 가짜뉴스일 확률이 올라갑니다.

2.2. 각 점수 추출: 반의어, 거리, 도치점수
중요단어를 추출한 후, 3가지의 점수를 추출하는 과정을 거치게 됩니다. 각 과정은 다음과 같이 계산됩니다.
2.2.1. 반의어 점수
반의어 점수는 Word2Vector와 반의어 Embedding을 사용하여 계산합니다.
Word2vector는 단어 그대로를 벡터화시킨 지표로, 비슷하게 사용되는 용어들끼리는 가깝게 위치하게 됩니다. 이 때, 이 거리가 가까우면 해당 단어 간의 비슷한 점이 있다고 판단할 수 있습니다. 이 “비슷하다”에는 동의어와 반의어가 모두 포함되는데요.
예를들어 각각 동의어와 반의어 관계를 지니는 ‘가로’, ‘세로’, ‘횡’, ‘종’은 (0,10), (1,9), (2,8), (3,7)과 같이 비슷한 거리 상에 위치하지만, 이들(거리방향)과 완전히 다른 ‘음식’에 해당하는 ‘햄버거’, ‘피자’ 같은 단어는 (10,1), (9,2)로 나타나게 됩니다.
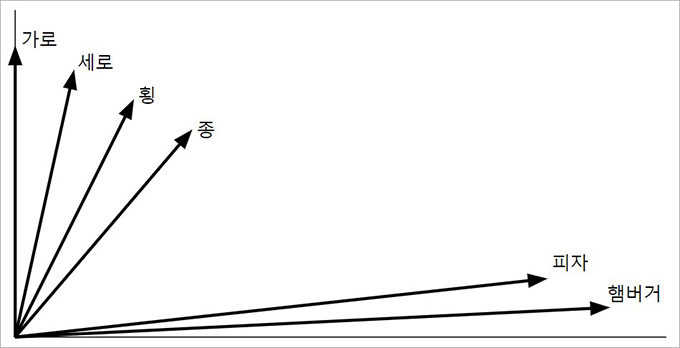
이러한 이유로, 반의어를 구분하기 위해 반의어 Embedding을 사용하여 여러 반의어를 미리 학습시켜두었습니다. 이를 통해 ‘가로’와 ‘횡’이 동의어고 ‘가로’와 ‘세로’가 반의어임을 학습시켰을 때, ‘종’이 입력되면 ‘종’과 ‘횡’이 반의어 관계일 확률을 점수로 나타낼 수 있게 되었습니다. 이 반의어 점수는 중요단어와 중요본문 단어가 반의어일 때 높게 측정되고, 그 점수가 높을수록 가짜뉴스일 확률이 올라가게 됩니다.

2.2.2. 거리 점수
거리 점수는 제목에 포함된 단어간 거리를 점수로 사용하는데요. 각 단어들 사이에 몇개의 단어가 놓였는지를 거리로 수치화한 뒤, 해당 수치에 비례한 점수를 부여합니다. 이 점수가 높다면 뉴스 제목에 임의의 흥미로운 단어를 삽입해 클릭을 유도했다고 판단하여 가짜뉴스일 확률이 올라갑니다.
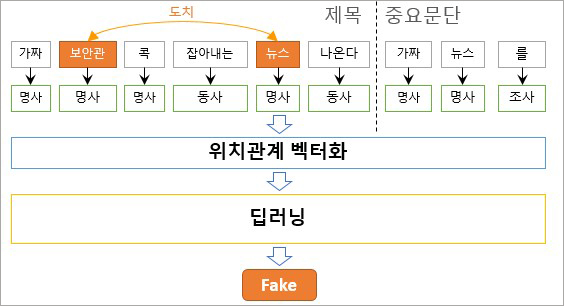
2.2.3. 도치 점수
마지막으로 도치 점수는 단어들의 상대적 위치 관계를 벡터화한 후, 임의의 두 명사를 도치한 학습 데이터를 이용하여 제목에 있는 단어가 도치되어 나타날 확률을 점수로 계산합니다. 해당 점수가 높게 나오면 제목에 추가적으로 삽입한 단어는 없지만, 순서를 꼬아서 본문 내용과는 다른 제목을 선정하였다고 판단하여 가짜뉴스일 확률이 올라갑니다.
2.3. 최종점수 산출
위와 같이 세가지 단계를 거치면서 받은 점수를 통합하여 점수가 높다면 해당 뉴스가 가짜라고 판단하게 되는데요.
처음 특허 소개 부분에서 인용한 문단과 비교하면 많이 이해가 되셨나요? 저희는 오늘 설명드린 가짜뉴스 판별 특허 외에도 많은 특허들을 등록했는데요. 다음에 또 다른 흥미로운 특허로 찾아뵙도록 하겠습니다 ^^ 감사합니다.
[관련 포스팅 보러가기] 포털 적용 사례로 알아본 NER 개념과 활용법 딥러닝 기반 연예뉴스분석시스템 개발기