안녕하세요, AI PLUS Tech Blog입니다. 오늘은 이스트소프트에서 개발한 고용률 예측 모델의 개발 과정을 소개드리려고 합니다. 지난해 이스트소프트 A.I. PLUS Lab의 NLP 파트에서는 뉴스 정보를 기반으로 한 고용률 예측 모델을 연구하였습니다.
1. 고용률 예측 모델의 필요성
현재 경제상황을 파악하는 좋은 방법은 어떤 것이 있을까요? 여러 나라에서는 현 경제상황을 파악하기 위한 다양한 지표(지수)를 개발하여 공개하고 있습니다. 이와 같은 수치를 참조함으로써 현재 상황에 대한 대략적인 파악이 가능하고, 이를 기반으로 다양한 결정들을 내릴 수 있는데요. 하지만 대부분의 지표는 사람의 노동력이 직접적으로 투입되어 다양한 설문이나 조사 등 수작업을 통해 수집되기 때문에, 단기간의 수치 변화를 알기 어렵다는 문제가 있습니다.
지난 2020년에는 코로나19의 확산으로 디지털 경제로의 전환이 빠르게 가속화되는 등 사회적으로 큰 변화가 생기면서, 보다 짧은 단위의 초속보성 경기지표의 필요성이 두드러지게 나타났습니다. 이에 따라 저희는 인공지능(AI) 기술을 활용하여 경제활동 주체들의 형태 변화 등 고용시장에서 발생한 큰 변화 흐름을 감지하고, 단기간의 고용률 변화를 예측하는 모델을 개발하기로 하였습니다.
2. 고용률 예측 문제 정의
고용률 예측 문제는 크게 보면 시계열 예측(time series forecasting) 문제로 볼 수 있습니다. 시간에 의존적인 데이터를 대상으로, 앞 시간의 데이터를 보고 뒤쪽 시간에 해당하는 값을 예측하는 문제인데요. 이 중에서도 해당 문제는 현황 또는 아주 가까운 미래를 예측하는 ‘현재 예보(nowcasting) 문제’로 볼 수 있습니다.
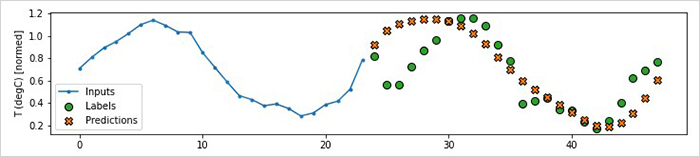
하지만, 고용률과 같은 지표의 미래 변화는 단순히 과거 값에만 의존하는 것이 아니라 외부 사건들(정부 정책, 경제 상황 등)의 영향을 받기 때문에, 기존 고용률 값과 외부 사건 정보를 같이 이용하여 현재 예보 모델을 구성해야 할 필요가 있었습니다.
이에 대한 선행 연구로서, 이스트소프트는 뉴스 기사를 활용하여 현재 고용 상태에 대한 심리 분석을 진행하고, 단기간의 고용률 변화를 현재 예보하기 위한 모델을 개발하였습니다. 이처럼 뉴스 정보를 이용하여 고용 지표를 추출하는 접근은 이전에도 있었지만 [2], 해당 논문은 머신러닝 기법을 적극적으로 사용하지 않았기 때문에 이번 프로젝트에서는 BERT 기반 모델을 이용한 방식으로 접근하였습니다.
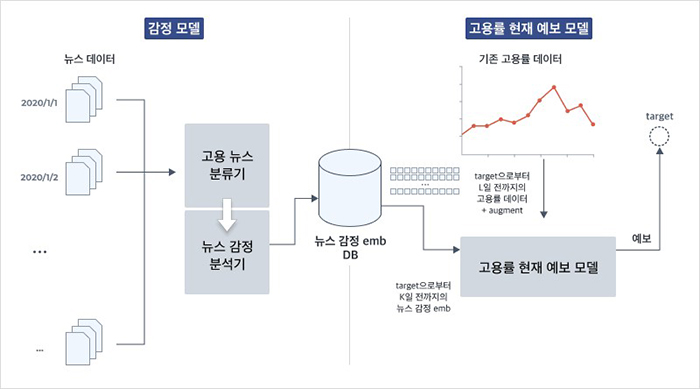
<그림2>와 같이 구성된 이 모델은 크게 두가지 모듈(감정 모델, 고용률 현재 예보 모델)로 나누어집니다. 뉴스 기사로부터 현재 고용 상황에 대한 감정(긍정/부정)을 추출하는 파트가 있고, 이를 이용하여 짧은 기간에 대한 고용률을 현재 예보하는 파트가 있습니다. 이번 포스팅에서는 <그림2> 왼쪽의 감정모델에 대한 내용을 중점적으로 다루고, 고용률 현재 예보 모델에 대한 자세한 설명은 다음 포스팅에서 다뤄보겠습니다.
3. 감정 모델 개요
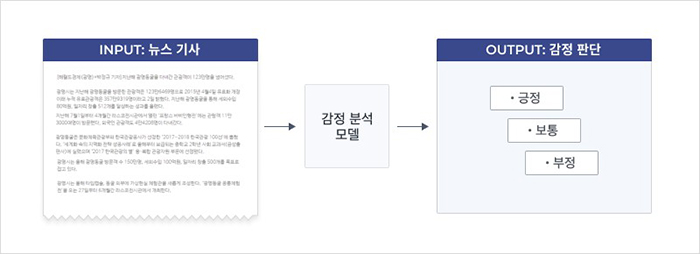
감정 모델은 뉴스 텍스트로부터 직접 고용 감정(긍정/부정)에 대한 정보를 추출하는 모델입니다. 감정 정보의 추출은 여러가지 접근 방법이 있을 수 있는데요. 이번 프로젝트에서는 뉴스 내용을 보고 해당 내용이 현재 고용 상태에 대해 긍정적인지 부정적인지 판단하는 모델을 학습한 후, 해당 모델이 추출한 뉴스의 문서 임베딩(document embedding)을 고용 감정에 대한 정보로 사용하기로 결정하였습니다.
이를 위해서는 뉴스 내용을 기반으로 고용 감정 레이블링이 필요한데요. 이 부분은 많은 고민을 한 끝에, 1) 주어진 뉴스가 고용과 관련된 뉴스인지 분류하는 단계와 2) 고용 관련 뉴스의 감정을 판단하는 단계로 나누어 진행하였습니다.
이 문제를 전체 4개(긍정, 중립, 부정, 고용관련이 아님)의 레이블로 구성하여 모든 뉴스를 대상으로 레이블링할 수도 있었으나, 이렇게 할 경우 전체 뉴스에 비해 고용과 관련되지 않은 뉴스의 비중이 너무 커져 데이터셋이 불균형해지는 문제(imbalanced dataset)가 발생할 가능성이 높았습니다. 더군다나 많은 양의 데이터를 확보하기 어려웠던 상황이라, 문제를 두가지로 구분하여 먼저 고용 관련 뉴스인지 추론하는 분류기를 만드는 것이 더 낫다고 판단하였습니다.
따라서 감정 모델은 <그림3>과 같이 해당 뉴스가 고용 관련 뉴스인지 구분하는 뉴스 분류기와 고용 뉴스를 대상으로 고용 감정을 분류하고 감정 정보를 뽑아내는 감정 분석기로 구성하였습니다. 이 중에서 딥러닝 모델로 구현되는 부분은 고용 기사 분류 모델과 감정 분석 모델이며, 각 모델들은 현재 NLP에서 가장 널리 사용되는 BERT[3] 기반의 모델을 사용하였습니다.

여기서 BERT 모델은 지난 2018년 구글이 처음 공개한 모델로, 대량의 데이터로 사전 훈련한(pre-trained) 모델을 다른 도메인에 맞추어 새로 학습하는 방식을 사용해, 적은 데이터로도 쉽게 학습을 진행해 좋은 성능을 낼 수 있다는 장점이 있습니다. BERT의 등장으로, 자연어 처리 분야는 사전 학습된 모델을 바탕으로 응용분야의 재학습을 진행해 단기간 내 뛰어난 성능을 낼 수 있게 되었고, 시간이 흐르면서 BERT의 성능을 높이기 위해 ALBERT [4], XLNet [5], DistilBERT [6], ELECTRA [7]와 같은 BERT 기반 모델들이 고안되었습니다.
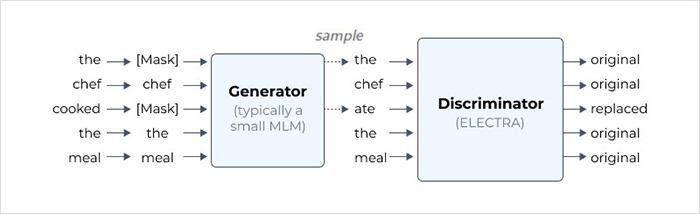
그 중에서 이번 감정모델 개발에 사용한 모델은 ELECTRA라는 모델입니다. ELECTRA 모델은 사전 학습 단계에서 GAN(Generative Adversarial Network)과 비슷하게 생성기(generator)와 판별기(discriminator)를 이용합니다. ELECTRA 모델을 학습시킬 때는 <그림4>와 같이 본격적인 학습 전에 문장에 마스킹(masking) 작업을 진행합니다. 이후 생성기가 마스킹된 단어를 예측해서 새로운 문장을 만들고, 이 문장을 가지고 판별기가 원본 문장과 일치하는지, 생성기가 생성한 단어인지를 판별하는 식으로 학습이 진행됩니다. 마스킹된 단어를 맞추는 방식으로 학습을 진행하기 때문에 모르는 단어가 나와도 그 성능이 쉽게 저하되지 않는다는 장점이 있습니다.
4. 감정 모델 세부 구조
앞서 <그림3>에서 살펴봤던 것과 같이 감정모델을 각 단계별(데이터 전처리, 고용기사분류모델, 감정분석모델)로 알아보겠습니다.
4.1. 데이터 전처리
AI 모델 개발에서 데이터의 양과 질은 모델의 성능을 좌우할 정도로 중요한 역할을 합니다. 이번 모델에서는 AI가 잘 훈련을 할 수 있도록, 데이터 자체를 정제하는 기사 필터링 작업(5개 유형)과 딥러닝 학습을 위해 텍스트 데이터를 토큰으로 변환하는 과정(Sentence Piece Tokenizer)을 거쳤습니다.

먼저 모델을 학습시키기 위해 다수의 기사들을 모았지만, 적절하지 않은 기사들도 포함되어있기 때문에 데이터 정제를 위해 <그림5>와 같이 5가지 유형의 데이터를 처리하는 필터링 작업을 진행하였습니다.
뉴스 기사 특성 상 한 가지 이슈에 대해서 여러 기사가 나오기 때문에, 비슷한 내용의 기사들을 삭제하기 위해 제목이 중복되는 기사들을 제거하였습니다. 또한, 객관적인 고용 감정 분석을 위해 특정 관점이 담긴 ‘고용동향’ 키워드가 포함된 기사도 삭제하였습니다. 더불어 해당 기사가 고용과 확실히 관련이 있어야 하기 때문에 74개의 고용 연관어가 무조건 포함되고, 현재 고용에 대한 입장이 들어갈 수 있도록 411개의 인용 어휘가 포함된 기사만을 사용했습니다. 마지막으로 기사의 길이가 너무 짧으면 필요한 데이터를 충분히 포함하고 있지 않을 수 있어 본문 길이가 200자 이하인 기사는 제외하였습니다.
이렇게 필터링 된 뉴스들은 sentence piece tokenizer를 통해 subword 단위의 토큰으로 변환하여 데이터 전처리 과정을 마쳤습니다.
4.2. 고용 기사 분류 모델
위와 같은 전처리 과정을 거친 뉴스 기사들은 <그림6>와 같이 고용 기사 분류 모델의 입력(input)으로 들어가, 해당 뉴스 기사가 고용 관련 뉴스 기사인지를 판정하는 과정을 거칩니다. 해당 모델의 입력값으로 기사를 넣으면 이 기사가 고용과 관련있을 확률과 관련없을 확률이 몇 퍼센트인지 출력값을 도출합니다. 이 모델은 간단하게 KoELECTRA와 fully-connected layer를 이용하여 구현하였으며, 레이블링 된 데이터셋을 통해 고용 관련 뉴스 기사 여부를 재학습(fine-tuning)하였습니다.

4.3. 감정 분석 모델
감정 분석 모델은 위의 고용 기사 분류 모델을 통해 ‘고용과 관련됐다’고 판단된 뉴스들에 대해 감정 정보를 뽑습니다. 모델 구성은 고용 분류 모델과 비슷하게 KoELECTRA와 fully-connected layer를 활용했으며, 모델의 학습 시에는 뉴스 기사로부터 추출된 고용 감정의 세가지 클라스(긍정/보통/부정)에 대한 확률을 학습합니다. 학습이 끝난 후에는 학습된 모델에서 맨 마지막 단계인 softmax 함수를 거치기 전의 임베딩을 이후 고용 감정 정보로 활용합니다.
5. 감정 모델의 학습 및 평가
감정모델을 구성하는 고용 기사 분류 모델과 감정 분석 모델에서는 BERT의 파생 모델을 사용하였습니다. 가장 성능이 좋은 모델을 찾기 위해 앞서 언급했던 BERT를 비롯해 파생 모델 5가지에 대한 학습과 평가를 진행하였고, 해당 과정을 소개해보겠습니다.
5.1. 평가 모델들
실험 대상은 한글 데이터로 사전 학습시킨 총 5가지 모델로, KoBERT, SKT KoBERT [8], DistilKoBERT [9], KoELECTRA [10], KoCharELECTRA [11]였습니다. 먼저 KoBERT와 SKT KoBERT는 모두 BERT 모델이지만, 학습 데이터나 파라미터를 다르게 학습시킨 모델입니다. DistilKoBERT, KoELECTRA, KoCharELECTRA는 BERT 기반 모델로, DistilKoBERT는 DistilBERT모델을 한글 데이터로 학습시킨 모델이며, KoELECTRA와 KoCharELECTRA는 ELECTRA 모델을 사용했지만, 각각 데이터를 형태소와 음절 단위로 나누어 학습시켰다는 점에서 차이가 있습니다.
5.2. 평가 데이터 구성
모델 학습과 평가를 위한 데이터는 표1과 같이 정부 사업을 통해 수집된 후 수작업으로 레이블링된 뉴스 데이터를 제공받았습니다. 고용 기사 분류 모델에서는 전처리를 거친 101,565개의 기사 데이터 중 81,252개에 해당하는 데이터를 학습에 활용하였고, 나머지 20,313개 데이터는 테스트에 활용하였습니다. 감정 분석 모델에서도 전처리를 거친 총 7,519개의 기사 중 6,015개의 기사를 학습에 활용하고, 이후 1,504개의 기사를 바탕으로 모델의 성능을 분석하였습니다.
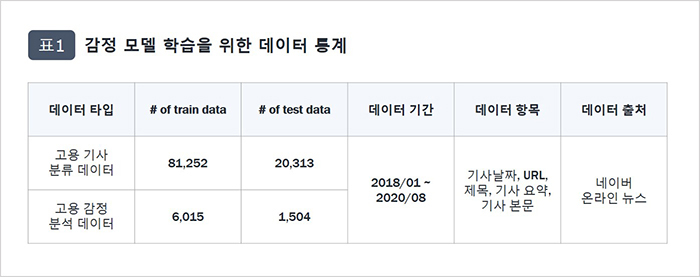
학습과 평가 데이터는 언급한 전처리 외에, 각 레이블의 통합을 위한 작업도 진행했습니다. 사람이 레이블을 수작업으로 진행했기 때문에 데이터의 균일한 정제와 품질 유지를 위해 별도 작업을 진행했는데요. 먼저 고용 기사 분류 모델에서는 두가지 정답만 존재하도록 했습니다. (①고용과 관련된 기사다, ②고용과 관련되지 않은 기사다) 반면, 고용 관련 기사에 대한 감정을 분석할 때에는 ‘감정’이란 특성 상 정답이 확실히 구분되기 어렵기 때문에 정답을 3종류(부정적, 보통, 긍정적) 또는 5종류(매우 부정적, 부정적, 보통, 긍정적, 매우 긍정적)로 나눈 데이터로 각각 실험을 진행했습니다.
5.3. 결과 비교
아래 표2, 3, 4는 학습을 진행한 총 5개 모델의 성능 결과입니다. 평가는 각 모델들에 대한 정확도(acc)와 f1 score를 측정하였습니다.
정확도는 정확히 예측된 데이터의 수를 전체 데이터 수로 나눈 값으로, 모델의 성능을 가장 직관적으로 나타낼 수 있는 평가 지표입니다. 하지만, 이는 데이터 자체의 비대칭을 고려하지 않는다는 문제가 있습니다. 예를 들어 고용 기사 분류 모델 학습에 사용되는 데이터 전체의 90%가 고용에 관련되어 있고, 그 나머지 10%가 고용과 관련되지 않은 기사라면 데이터 자체가 더 많은 고용 기사를 분류하는 성능은 높게 나오지만, 고용과 관련되지 않은 기사를 분류하는 성능은 낮게 나올 수 있습니다. 바로 이와 같은 데이터 불균형 문제를 보완하기 위한 지표가 f1 score입니다. f1은 데이터 구조가 불균형할 때, 모델의 성능을 평가할 수 있는 지표입니다. 이번 모델들을 학습하기 위해 사용한 데이터에 비대칭성이 존재하기 때문에, 모델들의 성능을 판단할 때에는 f1 score를 이용하였습니다.
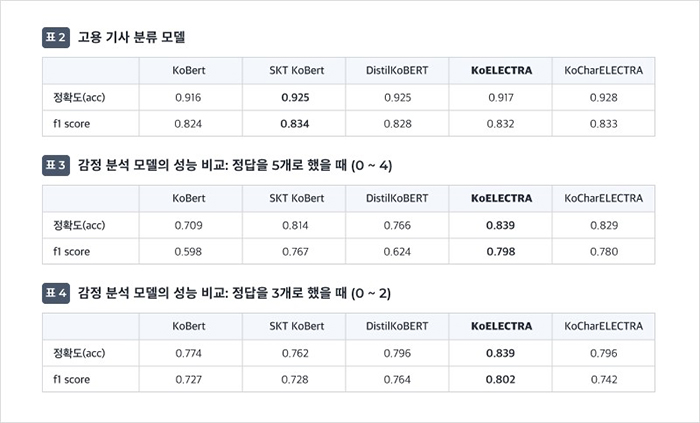
위의 표를 보면 KoELECTRA 모델을 사용했을 경우, 전반적으로 좋은 성능이 나타나는 것을 확인할 수 있습니다. 감정 분석 모델에서는 최대 성능치를 기록하였고, 고용 기사 분류 모델에서는 제일 높은 SKT KoBert 대비 0.002 낮은 값으로 2번째 높은 기록을 보였습니다.
KoELECTRA 성능 값이 대체적으로 우수하고 SKT KoBert과의 차이(0.002)도 적었기 때문에, 실제 ELECTRA 모델의 논문에서 BERT와 성능 비교 시 그 차이가 상당했던 점을 고려하여 고용 기사 분류 모델과 감정 분석 모델 모두에서 KoELECTRA를 사용하기로 결정하였습니다. 추가적으로 감정분석 모델의 성능을 비교했을 때, 정답을 3분류로 나눴을 때의 성능이 5분류보다 전반적으로 더 좋았기 때문에 정답 수 또한 3가지로 진행하기로 하였습니다.
더불어 기사 분류 모델과 감정 분석 모델의 성능을 비교해보면 고용기사 판단에서는 대체로 우수한 성과를 내지만, 이에 반해 감정분석 모델의 성능이 다소 낮은 수치를 보이는 것을 확인할 수 있습니다. 여러가지 이유가 있을 수 있지만, 우선 투입한 데이터 양에서 큰 차이가 발생했기 때문에 다소 성능의 차이가 있는 것으로 분석됩니다. 또한, 감정 데이터 특성 상 정확하게 답변이 나뉘는 것이 아니라, 데이터를 작업하는 사람의 주관이 들어가기 때문에 오류가 발생할 여지가 있습니다. 예를 들어 누군가는 해당 기사에 대해 부정적으로 볼 수 있지만, 다른 누군가는 긍정도 부정도 아니라고 판단할 수 있기 때문입니다. 하지만 이러한 문제는 해당 문제는 학습 데이터의 양이 많아진다면 긍/부정을 판단할 수 있는 기사의 수도 많아지기 때문에 해결될 수 있을 것으로 기대됩니다.
6. 마치며
오늘 소개드린 고용률 예측 프로젝트처럼, 텍스트 정보를 이용하여 시계열 정보를 예측하는 과제는 응용 분야가 넓은 만큼 활발한 연구가 이루어지고 있습니다. 특히 시계열 정보가 외부의 영향을 받을 경우 외부 정보를 추가로 사용할 필요가 있는데요. 이번 케이스처럼 서로 다른 특성들을 가진 여러 데이터들(기존 고용률, 뉴스 기사)을 같이 이용하는 머신러닝 분야를 멀티모달(multimodal) 머신러닝이라고 합니다. 딥러닝은 입력 정보를 임베딩 벡터의 형태로 추출할 수 있다는 특성에 기반해, VQA, 텍스트 기반 이미지 생성 등 서로 다른 특성을 지닌 데이터들을 같이 활용하여 복잡한 모델을 구성하는데 유용한데요.
본 프로젝트에서도 이런 딥러닝의 특성을 이용하여 시계열 정보와 텍스트 정보를 동시에 활용하는 모델을 구성하였고, 이번 포스팅에서는 그 중에서도 뉴스 정보로부터 고용 감정을 추출하는 모델에 대한 설명을 하였습니다. 다음 포스팅에서는 이 모델로부터 추출한 정보를 이용하여 어떻게 고용률 현재 예보 모델을 설계하였는지에 대해 다루도록 하겠습니다. 감사합니다.
참고문헌
[1] https://www.tensorflow.org/tutorials/structured_data/time_series#%EB%8B%A4%EC%A4%91_%EC%8A%A4%ED%85%9D_%EB%AA%A8%EB%8D%B8
[2] Shapiro, Adam Hale, Moritz Sudhof, and Daniel J. Wilson. “Measuring news sentiment.” Journal of Econometrics (2020).
[3] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[4] Lan, Zhenzhong, et al. “Albert: A lite bert for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942 (2019).
[5] Yang, Zhilin, et al. “Xlnet: Generalized autoregressive pretraining for language understanding.” arXiv preprint arXiv:1906.08237 (2019).
[6] Sanh, Victor, et al. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019).
[7] Clark, Kevin, et al. “Electra: Pre-training text encoders as discriminators rather than generators.” arXiv preprint arXiv:2003.10555 (2020).
[8] https://github.com/SKTBrain/KoBERT
[9] https://github.com/monologg/DistilKoBERT
[10] https://github.com/monologg/KoELECTRA
[11] https://github.com/monologg/KoCharELECTRA
[관련 포스팅 보러가기] 딥러닝 모델 압축 방법론과 BERT 압축