안녕하세요, AI PLUS Tech Blog입니다. 오늘은 지난달 소개드린 고용률 예측 모델의 개발 과정을 이어 설명드리려고 합니다.
지난 1편에서는 뉴스 기사로부터 고용 시장에 대한 감정 정보(긍정/부정/보통)를 추출하는 부분을 다뤘는데요. 오늘은 이렇게 추출된 감정 정보로부터 미래 고용률을 현재 예보(nowcasting)하는 과정에 대해 중점적으로 살펴보려고 합니다.
본격적인 개발 과정을 소개하기 앞서, 1편을 못 보신 분들은 1편을 먼저 확인해주세요!
AI를 활용한 고용률 예측 모델 개발기(1) 보러가기 >>>
1. 고용률 현재 예보에 대한 가정
먼저 현재 예보는 현재 상황 또는 아주 가까운 미래를 예측한다는 의미를 가지고 있습니다. 고용률 현재 예보 모델이 풀고자 하는 문제는 바로 과거 고용률 정보로부터 단기 미래값을 예측하는 것인데요.
하지만, 지난 포스팅에서 언급했듯이 고용률은 정부 정책, 경제 상황 등 외부적인 영향을 받기 때문에 과거 고용률 수치만으로는 미래값을 예측하기 어렵습니다. 이에 따라 이스트소프트 연구팀은 외부 영향을 고려할 수 있는 뉴스 기사를 추가 데이터로 사용하여 불충분한 고용률 정보를 보완하고자 했습니다. 최종적으로 구현된 고용률 현재 예보 모델은 뉴스 기사로부터 추출된 감정 정보(긍정/부정/보통)와 이전 고용률 수치로부터 확장된 정보가 결합되어 예측값을 도출하는 형태가 되는데요. 이 값을 수식으로 나타내면 다음과 같습니다.
먼저 yt+1 은 우리가 알고자 하는 고용률 예측값입니다. 여기서 xt:t-L 는 $t$시간부터 $L$시간까지의 과거 고용률 정보를 의미하고, et:t-W 는 $t$시간부터 $W$시간까지의 뉴스 감정 정보를 의미합니다.
여기서 주목할 점은 과거 고용률 정보와 감정 정보가 각각 다른 기간($L$과 $W$)을 참조하고 있다는 점인데요. 고용률은 1년 주기로 비슷한 형태가 반복되기 때문에 이 주기성을 고려해야 합니다. 따라서 주기성을 나타내기 위해 고용률 입력기간은 1년 정도로 가정하고, 뉴스의 경우 주기성보다 시의성이 더욱 중요하기에 최신 뉴스를 중점적으로 반영하고자 입력기간을 다르게 설정하게 되었습니다. <그림1>은 위 값들이 시간 $t$에 대해 어떤 관계를 가지는지 보여줍니다.
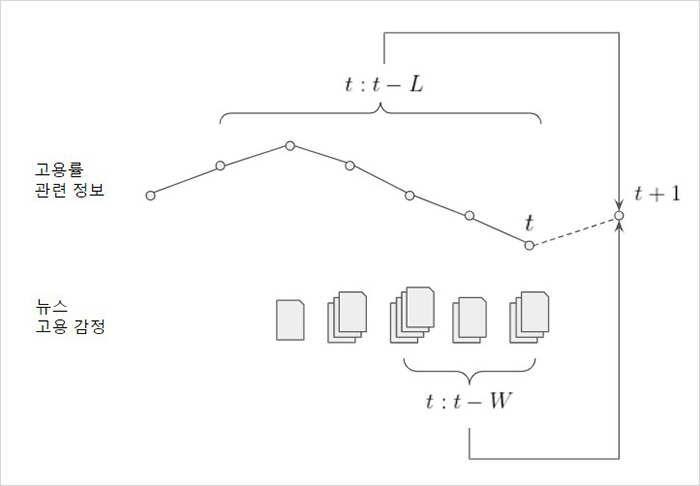
2. 초기 개발 과정에서 발생한 문제와 해결방법
고용률 현재 예보 모델의 초기 구상은 $W$기간에 해당하는 뉴스 전체에서 고용 감정 임베딩을 추출하고, $L$기간의 고용률 데이터를 함께 사용하여 현재 예보값을 구하는 것이었습니다. 하지만 실제 적용 과정에서 몇가지 문제가 있었고, 그 중 데이터 전처리와 관련된 대표적 문제 2가지와 해결방안을 소개하겠습니다.
2.1. 감정 정보의 처리: 주성분 분석(PCA) 사용
현재 예보에 활용되는 감정 정보는 $W$기간 데이터 전체에서 추출되기 때문에, 이 임베딩을 그대로 사용할 경우 해당 정보의 차원이 너무 커지는 문제가 있었습니다. 현재 컴퓨팅 자원으로는 처리가 불가능했기 때문에 이를 줄여야 할 필요가 있었는데요.
이를 해결하기 위해 주성분 분석(Principal Component Analysis; PCA) 방식을 활용하여 감정 정보를 저차원으로 축소하는 전처리 작업을 진행하였습니다. 차원을 줄이면 정보의 손실이 발생할 수 있지만, 주성분의 분산을 조사하는 것으로 손실 정도를 확인하여 해당 문제를 보완하였습니다. 주성분 분석을 통한 차원 축소 후에도 기존 정보의 95% 정도가 남도록 임베딩을 $K$차원으로 줄였습니다.
다만, 이렇게 차원을 축소하면 해당 기간의 뉴스 개수가 축소된 차원 값보다 크거나 같아야 한다는 제약이 존재하게 되는데요. 이에 따라 현재 예보하려는 날짜로부터 3일($W=3$) 이내에 24개의 뉴스($K=24$)가 없는 경우는 데이터에서 제외하였습니다. 또한, 뉴스가 지나치게 많아도 컴퓨팅 자원의 한계상 모든 데이터를 사용할 수 없기 때문에 최대 뉴스 개수를 128개로 제한하였습니다.
2.2. 기존 고용률 정보의 처리: 데이터 증강(augmentation)
고용률 정보는 학습에 사용되는 데이터인 동시에 예측 대상이 되는 데이터입니다. 일반적으로 딥러닝 모델을 학습하는데에는 많은 데이터가 필요한데요. 주어진 고용률 데이터의 양과 정보가 너무 적다는 어려움이 있었기 때문에 실제 입력 데이터를 늘리기 위해 데이터 증강(augmentation) 방식을 활용하였습니다.
데이터 증강 단계에서는 첫째로 주기성 등을 직접적으로 나타내어 모델이 보다 쉽게 학습될 수 있도록 하였는데요. 고용률 데이터에서 날짜 정보는 일련의 주기(period)를 가지기 때문에 매우 유용한 정보로 볼 수 있습니다. 다만, 이를 딥러닝 모델의 입력값으로 사용하기 위해서는 모델이 주기를 인지할 수 있도록 변환하는 과정이 필요합니다. 예를 들어 사람은 2019년 1월 1일과 2018년 1월 1일의 데이터를 보면 한 주기(1년) 만큼의 차이가 있다는 점을 쉽게 인지하지만, 딥러닝 모델은 이를 단순한 index(2018년 1월 1일이 0번이라면 2019년 1월 1일은 365번으로 인코딩됨) 또는 숫자(20180101, 20190101)로 인식해 이같은 주기적 특성을 인지하기 어렵기 때문인데요. 따라서, 딥러닝 모델에 날짜 정보를 넣을 때는 sin, cos을 이용하여 1년 주기의 신호로 변환한 값(year sin, year cos)을 만들어 입력값으로 사용하였습니다. 이를 통해 2019-01-01과 2018-01-01이 입력 단계에서 같은 sin/cos 값을 가지도록 조정해 두 값의 관계성을 부여하였고, 같은 날짜의 고용률 등 추가 값을 바탕으로 1년 주기의 두 값을 연결하고자 하였습니다.
이밖에도 고용률 현재 예보 모델은 예측 날짜로부터 가장 최근에 수집된 고용률 데이터를 사용하는데요. 이렇게 되면 예측일과 최종 고용률 집계일 사이의 모든 기간에는 동일한 고용률 정보가 사용되기 때문에 데이터 증강 단계에서 예측일과 최종 고용률 집계일이 얼마나 기간이 떨어져있는지 그 차이 정보(offset)를 명시적으로 부여하는 과정을 거쳤습니다. 예를 들어 2020/12/15에 대한 현재 예보를 위해서는 실제 수집된 최근 정보인 2020/12/1부터 $L$ 길이만큼의 고용률 값을 가져오게 되는데, 이 경우 offset 값을 14로 부여하는 것입니다.
위 데이터들은 각기 다른 scale과 적은 정보량을 가지고 있어 모델이 쉽게 학습될 수 있도록 고용률 값들을 정규화하고, offset 값은 31로 나누어서 0~1 사이의 값으로 scale을 맞추었습니다. 또한, 데이터 증강 외에 고용률 데이터를 일(日) 단위로 보간(interpolation)하는 방식을 통해 데이터의 양이 적다는 문제를 해결하려고 하였습니다. 시계열 데이터의 보간법은 여러가지가 있으나, 여기에서는 2차 곡선을 이용한 fitting 방식을 사용하였습니다.
3. 최종 고용률 현재 예보 모델
3.1. 데이터 구성
고용률 현재 예보 모델의 입력값으로는 각각 위와 같은 전처리 과정을 거친 감정 정보와 고용률 데이터가 투입됩니다. 특정 날짜(e.g. 2020/12/15)의 고용률값을 현재 예보하기 위해 실제 모델에 들어가는 데이터를 살펴보면 아래와 같이 구성되는데요.
먼저 뉴스 감정 정보는 24 x 128차원 vector로 구성됩니다. 이는 24 차원 PCA vector x 예보 3일 내의 최대 뉴스 기사 개수 128개를 의미합니다.
고용률 정보의 경우, 해당 날짜로부터 가장 가까운 기존 고용률 값을 찾고 그로부터 1년만큼의 고용률 정보(e.g. 2019/12/1~2020/12/1)를 모은 vector를 사용하게 됩니다. 이에 따라, 5 x 366차원의 vector로 구성되는데요. 이는 {(정규화된 고용률 값 + year sin + year cos + 정규화 된 이전 년도의 고용률 값 + offset) * 1년}을 의미합니다.
3.2. 모델 구조
모델 구조를 살펴보면 고용률 현재 예보 모델은 1편에서 다룬 감정 정보 결합 모델과 고용률 정보 결합 모델로 구성됩니다. 먼저 감정 모델은 목표 날짜를 포함하여 일정 기간(window) 동안 수집된 뉴스 기사로부터 추출된 정보에 PCA를 적용한 값(et:t-W)을 입력으로 받아, 하나의 대표 정보를 만들기 위해 transfomer encoder 모델, 집합(aggregation), 정규화(batchnorm) 과정을 거칩니다. 고용률 정보 모델의 경우 예측일에서 가장 가까운 고용률 데이터로부터 정해진 기간($L$) 만큼의 고용률 정보(et:t-L)를 입력으로 받아, 비슷한 방식으로 대표 정보를 만드는데요. 이렇게 만들어진 두 정보를 다시 통합한 후, 최종적으로 몇 개의 fully-connected layer와 batch normalization layer, relu, residual connection를 통과해서 예보값이 도출됩니다. 이 전체적인 흐름은 <그림 2>와 같습니다.
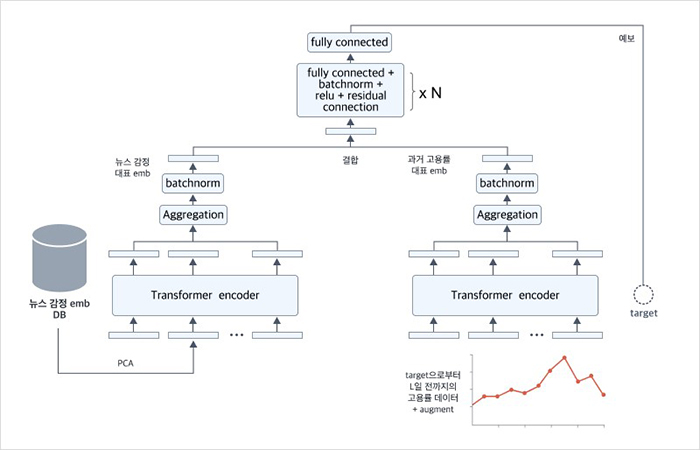
이때, 각 모델은 self-attention 특성을 가지고 있는 transformer-encoder 모델을 사용했는데요. 일반적으로 딥러닝에서 고용률과 같이 시간 순서가 있는 데이터를 처리하기 위해서는 RNN 계열 모델들(e.g. LSTM, GRU)을 주로 사용하게 됩니다. 하지만 RNN로 시도했을 때, 성능이 예상보다 좋지 않아 transformer 모델을 사용하게 되었는데요. 고용률 예측을 위해서는 지난 1년간의 고용률 값을 입력해야 목표 날짜와 가까운 정보를 얻을 수 있는데, (e.g. 2020년 6월 1일 부근의 정보를 알기 위해서는 2019년 6월 1일 부근의 정보가 필요함) RNN은 모델 특성상 데이터를 순차적으로 처리하기 때문에 오래된 데이터일수록 그 비중이 낮아지는 관계로 1년 전 정보가 희석되어 유의미한 성능을 내기 어려웠던 것으로 분석됩니다.
반면, self-attention 특성을 가진 transformer 모듈은 입력 길이가 긴 경우에도 전체 시간에 바로 접근할 수 있기 때문에, 오래된 과거의 입력 값이라도 그 정보의 의미가 유지되어 좋은 성능을 나타낼 수 있었습니다 [1]. 여기서 self-attention 구조는 여러 개의 입력들이 주어졌을 때, 유사도를 기반으로 입력값을 ‘섞어’ 새로운 정보(embedding)를 만들어내는 특징이 있는데요. 이때 효율적으로 학습될 수 있도록 결과값에 더 큰 영향을 주는 입력값에 가중치를 부여합니다.
4. 실험 결과
4.1. 데이터 처리
모델의 학습 및 평가를 위한 고용률 데이터는 통계청 고용률(시도) 데이터의 전체 합계 고용률을 사용하였습니다. 학습과 테스트 데이터는 전처리 등에 문제가 없도록 고용률 데이터와 뉴스 데이터의 기간이 겹치는 특정 기간을 설정해, 2016/1/1부터 2020/8/31까지의 고용률 데이터를 현재 예보 대상으로 삼았습니다. 데이터의 기간을 섞으면서 기간에 따른 정보가 섞이지 않도록 데이터 자체를 섞지 않고, 전체 기간을 7:3으로 나누어 학습/테스트 데이터를 구성하였습니다. 시계열 데이터에서 이와 같은 데이터 분할 방식은 표본 외(Out-of-sample) 방식이라고 하며, 전통적으로 시간에 의존적인 데이터를 평가하기 위해 주로 사용됩니다 [2].
총 데이터의 양은 각각 train 1,185개, test 506개로, 상대적으로 적은 데이터의 정보와 양을 보완하기 위해 앞서 언급했듯이 데이터의 특징에 대한 증강 기법과 보간 방식을 활용했습니다. 자세한 구성은 아래 <표1>과 같습니다.
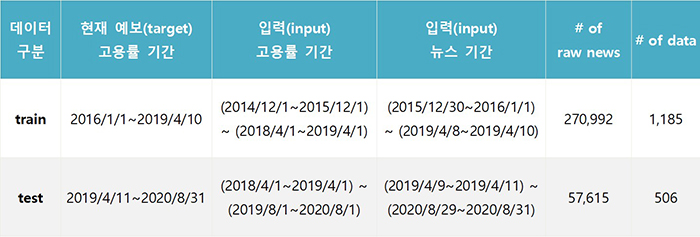
학습 데이터로는 2016/1/1부터 2019/4/10까지의 실제 고용률 데이터를 사용하였고, 입력값으로 예보일로부터 2년 전까지의 고용률 데이터와 해당 날짜부터 3일 전까지의 뉴스 데이터를 같이 사용하였습니다. 예를 들어 2016/1/1의 고용률을 현재 예보하기 위해서는 2014/12/1부터 2015/12/1까지의 고용률 데이터와 해당 데이터를 augment 한 데이터를 사용하며, 뉴스 데이터로는 2015/12/30~2016/1/1의 데이터를 사용했는데요.
또한, 테스트 데이터로는 2019/4/11부터 2020/8/31까지의 고용률 데이터를 사용하였고, 입력값으로는 예보일로부터 1년 전인 2018/4/1부터 2019/4/1까지의 고용률 데이터와 예측일을 포함한 3일치의 뉴스 데이터를 사용했습니다. 예를 들어 2020/8/31의 현재 예보를 위해서는 2019/8/1부터 2020/8/1까지의 데이터와 augment 된 데이터, 2020/8/29~2020/8/31의 뉴스 데이터가 사용되는 것입니다.
4.2. 결과 비교
결과 비교는 테스트 데이터를 대상으로 실제 고용률과 현재 예보 고용률 간의 상관계수(Pearson correlation coefficient)를 측정하는 방식으로 이루어졌습니다. 고용률 데이터의 경우 데이터의 양이 적은 만큼 모델의 학습에 따른 성능 변화가 있을 수 있으므로 10번의 학습을 진행하여 테스트 기간(2019/4/11 ~ 2020/8/31)에 대한 고용률 10개를 현재 예보했습니다. 이 값들의 평균을 내어 실제 고용률과의 상관계수(Pearson correlation coefficient)를 측정하였고, 0.5934로 양의 상관관계가 나타났습니다. <그림3>의 좌측은 실제 고용률(파란색)과 현재 예보 고용률(주황색)을 함께 표시한 그림이고, 우측은 동일한 기간에서 일주일 간격을 표시한 것입니다.
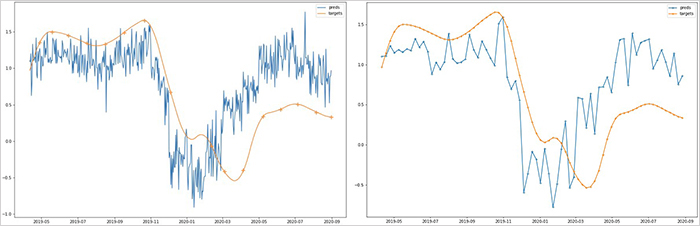
전체적인 고용률의 경향성을 한눈에 쉽게 보기 위해 전체 학습 기간과 테스트 기간의 고용률을 <그림4>와 같이 그려봤는데요. 해당 그림을 보면 고용률 현재 예보 값이 학습 기간에서 반복되는 패턴(감소→증가)을 잘 학습하였고, 전체적인 고용률 추세도 잘 반영하고 있음을 알 수 있습니다.
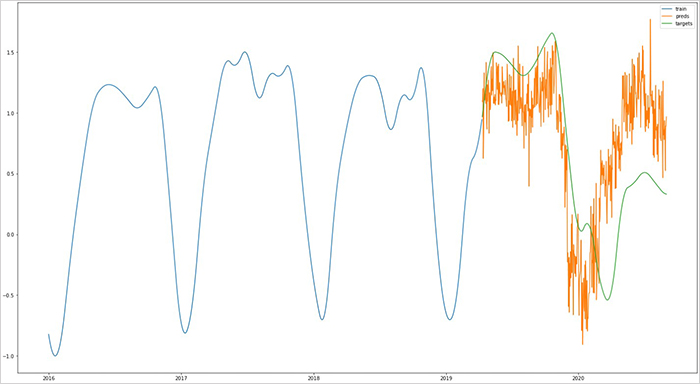
하지만, 코로나 발생 기간에 해당하는 2020년 1월부터는 현재 예보한 고용률 값과 실제 고용률 값 간의 상당한 차이가 나타나고 있음을 볼 수 있는데요. 코로나와 같이 예상치 못한 사건이 발생할 경우, 계산된 값의 경향은 맞지만 값의 크기가 실제 값보다 더 크거나 작게 나올 수 있는데(overshoot/undershoot), 이번 케이스도 그런 형태인 것으로 분석됩니다.
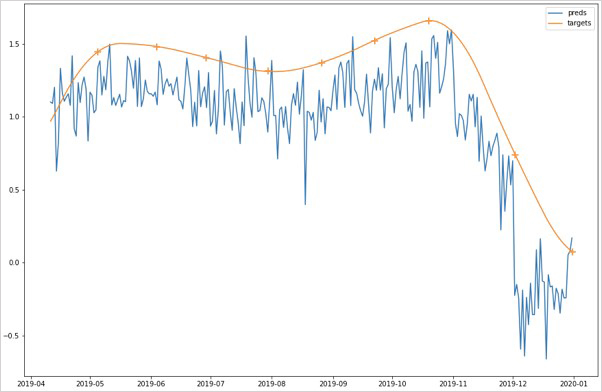
특수한 사건이 발생하지 않았을 경우의 모델 성능을 확인해보고자 코로나 발생 이전의 특정 기간을 설정해 추가적인 실험을 진행하였고, <그림5>와 같은 결과를 얻었습니다. 2019/4/11부터 2019/12/31까지를 대상으로 실제 고용률과 현재 예보 고용률 값의 상관계수를 보았을 때, 0.9304의 높은 양의 상관관계가 나타나는 것을 확인할 수 있었습니다. 이 점을 고려할 때, 일반적인 상황이라면 해당 모델을 고용률에 대한 현재 예보 용도로 사용할 수 있다고 판단됩니다.
5. 향후 과제 및 마무리
해당 모델은 테스트 기간에서 고용률의 경향성을 학습한 것으로 보이지만, 코로나 영향으로 실제 고용률값과 현재 예보값에서 차이를 보이고 있는데요. 시계열 데이터에서 모델이 이와 같은 현상까지 학습하여 정확한 값을 예측하기는 쉽지 않습니다. 이같은 특수 사건은 드물게 발생하고, 사건마다 미치는 영향이 매번 다르기 때문에 오히려 이같은 사건의 영향을 모델에 학습시키는 것보다, 이상치 탐지(anomaly detection) 방법을 이용하는 것이 좋다고 생각됩니다. 뉴스 내용을 바탕으로 예측에 강한 영향을 주는 이상 사건이 발생하였는지 판단하는 모델을 개발하거나, 베이지안기법을 통해 예측치의 신뢰도를 추가 표시하는 방법 등으로 해당 문제를 보완할 수 있을 것으로 보입니다.
지금까지 이스트소프트에서 개발한 텍스트를 이용한 고용률 현재 예보 모델에 대해 알아보았는데요. 내용이 많고 다소 복잡한 부분들도 있어 두 포스팅으로 나누어서 전달해드렸는데, 해당 내용이 앞으로 뉴스와 시계열 데이터를 이용한 연구를 하시는 분들에게 조금이나마 도움이 될 수 있으면 좋겠습니다. 감사합니다.
참고문헌
[1] Vaswani, Ashish, et al. “Attention is all you need.” arXiv preprint arXiv:1706.03762 (2017)
[2] Cerqueira, Vitor, Luis Torgo, and Igor Mozetič. “Evaluating time series forecasting models: An empirical study on performance estimation methods.” Machine Learning 109.11 (2020): 1997-2028.
[관련 포스팅 보러가기] 딥러닝 모델 압축 방법론과 BERT 압축